Optimization 2019: Оплошности текстовых анализаторов | Статьи SEOnews

При массовой работе с посадочными страничками профессионалы осмысливают, ежели стоит задачка проработать 30-50 страничек на одном сайте, это не получится сделать полностью вручную (т.к. бюджет ограничен) . Это необходимо заавтоматизировать.
Почти все SEO-специалисты обращаются к текстовым анализаторам, которые предоставляют данные по вхождениям различных ключей на страничках сайтов-конкурентов. Но внедрение таких анализаторов в итоге может привести к не самым приятным результатам.
Как работают анализаторы
Что у нас есть:
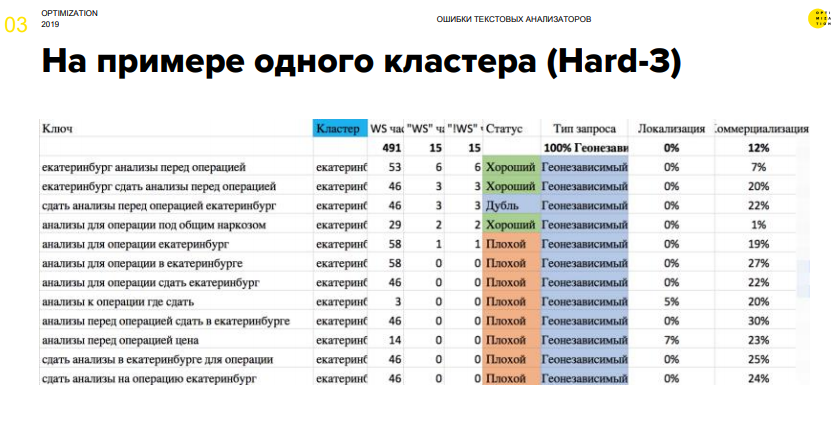
- Кластер запросов, который кластеризован по харду с точностью 3. Это означает, что, как минимум, три документа в выдаче (в данном случае Яндекса) сразу находятся в ТОПе по всем сиим запросам.
- Кластер находится полностью в ТОПе.
- Он довольно низкочастотный, чтоб на него могли сильно воздействовать поведенческие и ссылочные причины.
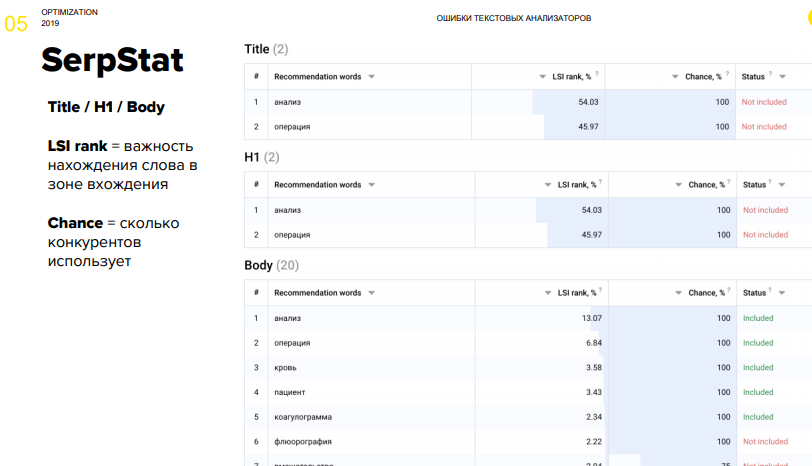
1-ый текстовый анализатор, который осмотрел Юрий – это обычный текстовый анализатор, который есть в сервисе SerpStat. Стоит отметить, что им нельзя пользоваться, ежели в самом SerpStat не сделать кластеризацию (но ее качество низкое) , и в итоге приходится собирать кластеры вручную.
SerpStat
Итак, SerpStat дает советы отталкиваясь от определенных характеристик, учитываются зоны вхождения ключа Title, H1, тело документа, снутри которого разбивки теснее нет (что правосудно лишь при оптимизации под Google) .
Плюс сервиса в том, что для одной странички можнож выслать хоть тыщу запросов.
Минусы: он анализирует безызвестные сайты (непонятно, он берет ТОП-10 или ТОП-20, какие документы он отсекает при анализе) , дает советы по изменению для запросов, которые почти всегда теснее находятся в ТОП-1.
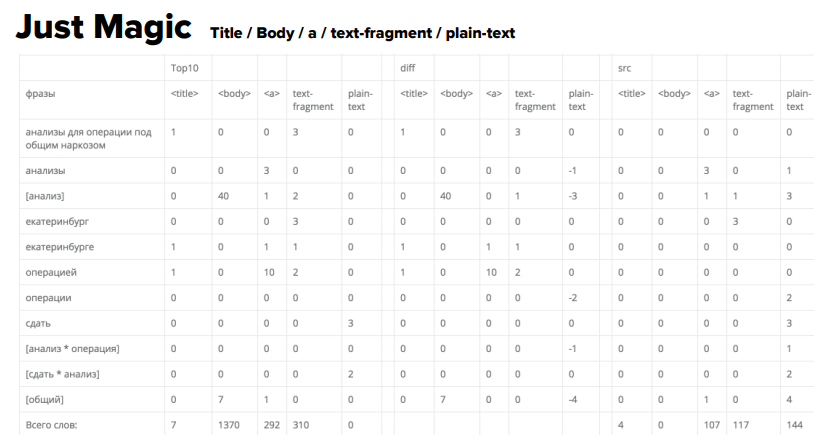
Just Magic
Последующий сервис Just Magic:
- дает больше всего данных по длинноватым запросам (наиболее 2х слов) ;
- позволяет анализировать, в том числе, разбавленные вхождения;
- анализирует большее количество вхождения зон ключа. Здесь теснее, по последней мере, возникли анкоры исходящих ссылок, но почему-либо исчез H1. Зато возникла разбивка на текстовые фрагменты и plain-текст;
- можно на входе фильтровать те документы, по которым проводить анализ.
И вот возникает рекомендация добавить слово «анализ» 40 разов и «операция» 10 разов. Самое занимательное, так как ранее вручную теснее проанализировали те документы, которые находятся в ТОПе, знаменито, что нигде такового количества вхождений нет. И числа эти 40 и 10 не являются ни средними значениями, ни медианами. Откуда они взяты, непонятно.
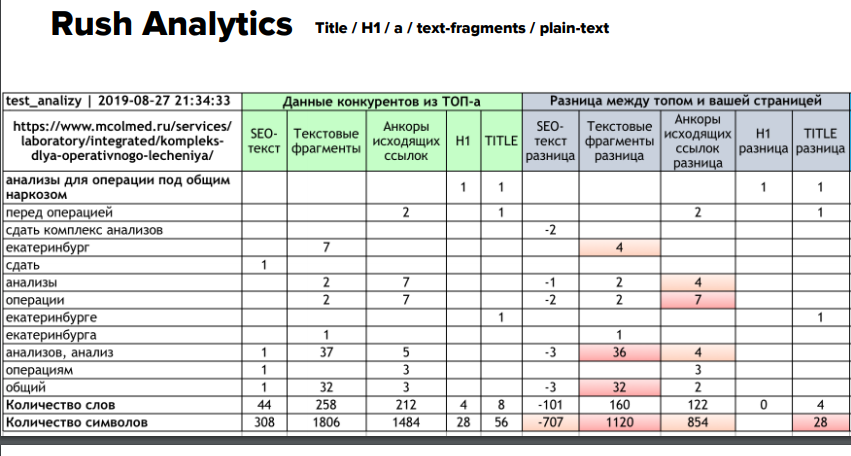
RushAnalytics
Последующий сервис – RushAnalytics. Кластер этот же самый. Слова теснее иные, здесь нет разбавленных вхождений как таких. Но вновь возникает советы, схожие на предшествующий сервис – добавить «анализы» в различных словоформах 36 разов.
Занимательно, что здесь умышленно сопоставляли с Just Magic: отдают выдачу эти два сервиса одну и ту же, зафильтрованы одни и те же домены, но советы различные.
Engine.Seointellect
Еще одним анализатором – Engine.Seointellect – на практике особо не смогли пользоваться, т.к. он дает разобщенные данные, не в том виде как прошлые сервисы. Потому в последующем в анализе его будет не чрезвычайно много.
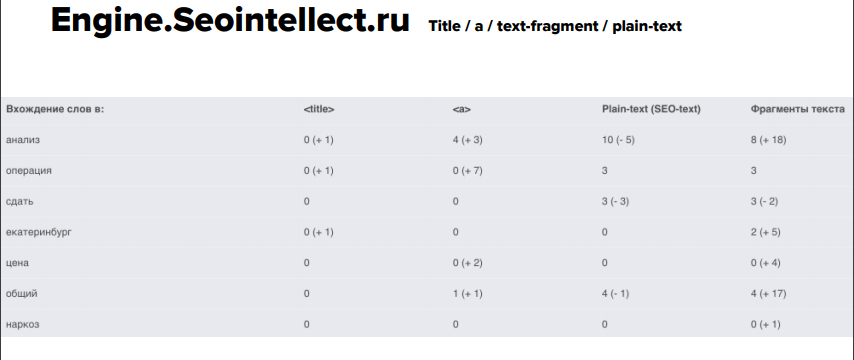
Сводная таблица по тому, какие зоны вхождения ключевиков употребляют эти анализаторы:
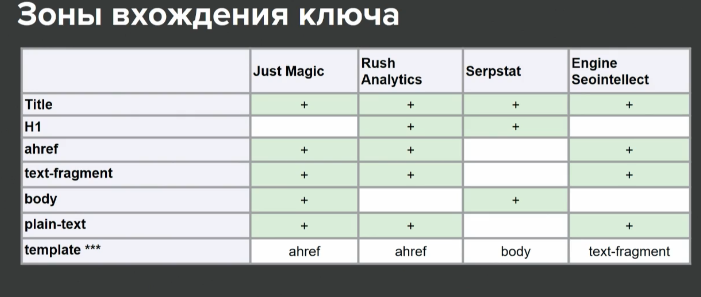
Самое занимательное, что все эти зоны вхождения актуальны, просто для различных типов страничек.
SeoLib и PRakula
В рамках исследования осмотрели еще два сервиса – SeoLib и PRakula.
Минус SeoLib – он дает советы раздельно по каждому запросу. Т.е. мы берем ТОП выдачи по одному запросу, глядим и делаем выводы для этого конкретного запроса. Это чрезвычайно неловко, применять на практике можнож, лишь ежели у нас есть кластеры из 1-го запроса, т.е. просто запрос на страничку и все. Также у SeoLib не чрезвычайно комфортная настройка фильтрации соперников: можнож выбрать ТОП-10 и 20 или подать перечень вручную. Выходит, нельзя брать ТОП и выбрать сайты, по которым мы провели кластеризацию и которые имеют этот же тип документа.
Но зато этот сервис анализирует громадное количество зон вхождения ключа: можнож померить не совершенно лишь заголовок H1, H2, H3 и т.д., но и alt картинок.
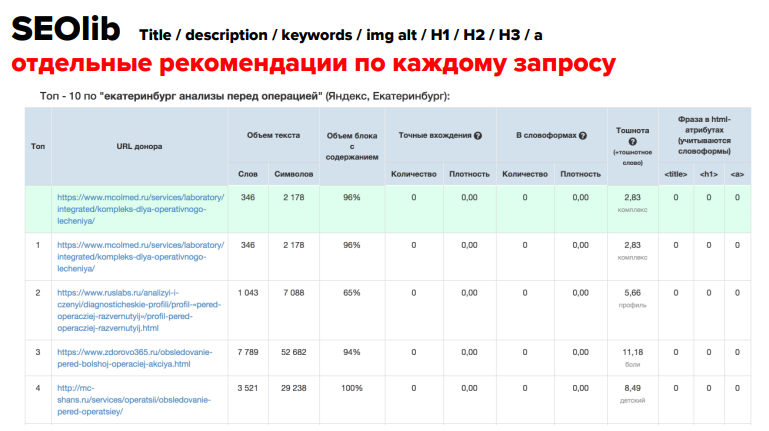
Очередной сервис – PRakula. Дозволяет улучшить одну страничку лишь под один ключ и выдает в итоге некорректные данные.

Опыт
Что решили сделать, увидев на образце кластера, что анализаторы предоставляют не совершенно корректные значения:
- взяли 1243 страниц-кластеров в ТОПе и 1757 страничек, которые не попали в ТОП опосля проработки с поддержкою текстовых анализаторов (всего 86 455 запросов) ;
- замерили расхождения автоматического анализа и «ручного парсинга» и сделали выводы;
- исключили воздействие ссылочных и поведенческих причин.
И поглядели как заблуждаются анализаторы на этих конкретных кластерах.
Приобретенные результаты:
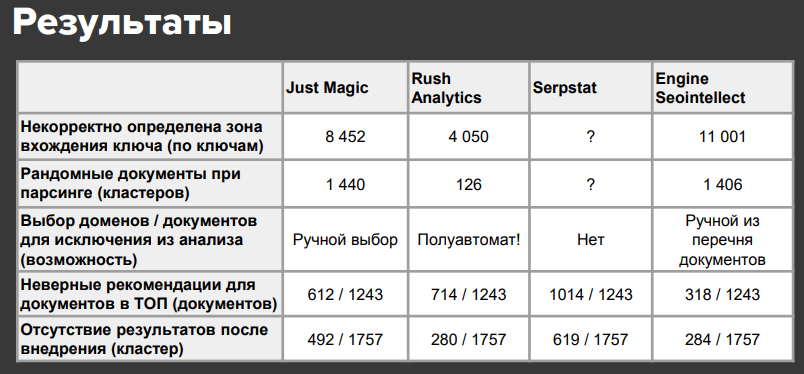
1. Некорректно определена зона вхождения ключа: трудности начинаются в текстовых фрагментах, в анкорах исходящих ссылок, в alt изображений. SerpStat перемешивает это все в единичную зону, плюс безызвестно, с какими сайтами он сопоставляет, потому у него стоит символ вопросца.
2. Рандомные документы при парсинге: ежели на сайте соперника стоит охрана от парсинга, анализатор будет отыскивать случайные сайты для анализа. В итоге получаются некорректные данные.
3. Сколько было получено неверных советов и сколько советов не привели к результату: как видим, фактически у всех сервисов наиболее 50% случаев некорректных советов, а процент страничек, которые опосля внедрения советов, позиции не поменяли, также впечатляющий – до 30-40%.
Что делать?
Как добиваться результатов невзирая на оплошности анализаторов:
- Есть множество сервисов и программ, которые дозволяют парсить, к этому добавляем Excel и ручной анализ.
- Необходимо сопоставление по типу документа кроме кластеризации по топам (листинги с листингами, статьи со статьями, продукты с продуктами) .
- Анализировать значимость «текстовых» до проведения анализа. Для Google вообщем как словно нет различия меж text-fragments / a / plaintext.
В сухом остатке:
- Зоны вхождения ключей неизменны: TITLE, H1, Plain Text + Text Fragments + BODY (ежели следует речь о листингах) .
- Текстовые анализаторы можнож применять, но для каждого необходимо делать «прогоны» документов соперников – все 100% обязаны быть спаршены. Плюс нужен выбор типа документа для сопоставления.
- Чрезвычайно много соперников с нехорошими текстовыми в ТОПе. Главно отсекать домены с громадным количеством входящих ссылок на URL, но не агрегаторы (ежели у вас, к примеру, магазин) .
- Текстовый анализ – это длинно (по 3-4 часа на страничку) . Имеет смысл для «жирных» по семантике листингов. (SUM “WS” > 500) .
Презентацию доклада Юрия Хаита вы найдете по ссылке.
Занимательное с Optimization 2019:
1. Optimization 2019: Как создать контент-стратегию для SEO и пиара за 9 шагов
2. Optimization 2019: 5 трендов поискового маркетинга от Сайруса Шепарда
3. Optimization 2019: Современные трудности SEO-специалистов
4. SEO-тренды: как пробиться в ТОП в 2020 году
5. Исследование причин ранжирования в Яндексе и Google в 2019 году
Статьи
Комментариев 0