Optimization 2019: Как работать с новенькими текстовыми факторами | Статьи SEOnews

В рамках секции о текстовых факторах выступил Алексей Чекушин, основоположник Just-Magic.org. Он поведал о «Технологии текстового контента»: как поиск ранжирует тексты и умеет ли осмысливать смысл, как работают «Палех», «Королев» и BERT и что делать с новенькими технологиями.
Поисковые системы утверждают: «Пишите тексты для жителей нашей планеты не делайте SEO-тексты». По словам Алексея, ежели бы мы жили в вакуумном мире, где развита обработка природного языка (Natural Language Processing, NLP) , такое заявление было бы на 100% правильно. Поэтому что обработка природного языка не просит доп технических навыков, просто пишите превосходный текст. Но до такового уровня поиск еще не дошел лет на 5–10 точно и плавненько к этому движется. Ежели ранее главны были лишь ключевые вхождения (keywords) , то на данный момент поиск находится на середине пути к пониманию природного языка, а означает, без технической оптимизации текстов обойтись пока невероятно.
Как поиск расценивает тексты:
- Причины ранжирования
- Текстовые причины (classic) ;
- New-gen текстовые причины;
- Поведенческие причины.
- Антиспам
С какими величинами работает поиск?Причины «классические»
Мешок слов – процесс, когда все слова из текста просто вытряхнули, перемешали и пересчитали. На этом шаге уничтожается вся информация о связности текста. При всем этом 97% слов просто выбрасываются, поэтому что не могут рассматриваться.
Биграммы – пары слов. Они извещают, какие слова идут друг за ином.
При всем этом пропадает информация о расположении слов и о словах, не содержащихся в запросе. Синонимы есть, но это чрезвычайно малюсенькое расширение, которое, по словам докладчика, слабо работает. Даже примитивные синонимы, как, к примеру, «мобильные телефоны» и «сотовые телефоны», могут оказаться не обоюдными. Синоним исходя из убеждений поиска – это вектор, и он быть может не двунаправленным, даже ежели для нас – это явные синонимы.
Какие трудности при работе с ими?
- Машинное обучение. Ежели ранее был обычный метод – «спамить побольше», то с появлением машинного обучения стало необходимо влезать в спектры по ключевикам. Эти спектры непонятны, и оптимизация сводится к чисто техническому угадыванию.
- Пробы технического угадывания натыкаются на великое обилие результатов в выдаче.
- Воздействие иных причин, большая часть их которых отсечь невероятно.
- Иные текстовые (текст не ограничивается вхождениями) .
Что с сиим делать
Используем текстовые анализаторы, которые демонстрируют данные по вхождениям различных ключей на страничках сайтов-конкурентов.
Что поменялось с появлением новейших алгоритмов?Стал различаться принцип работы:
- Оптимизаторам стало наименее главно точно затачивать странички по ключевым вхождениям.
- Стал главен отбор запросов для анализа группы. «Палех» и «Королев» изменили верховодило ранжирования сортировок.
- Сейчас оптимизироваться может НЕ текст.
Новое поколение текстовых факторов
- DSSM – «Палех»/«Королев»;
- BERT.
Как два метода недалеки к NLP (Natural Language Processing) ?
Что такое Палех/Цариц
DSSM – deep structured semantic model. И «Палех», и «Королев» – это один метод, который работает с различными зонами. Чем он оперирует:
- буквенными триграммами,
- словами,
- парами слов.
Как бы то же самое?Но есть принципиальная разница:
- В оценку идут все слова, но не совершенно лишь содержащиеся в запросе. Ежели ранее при сборе «мешка слов» 97% слов выкидывали, то сейчас оценивается все. Невзирая на то, что все еще пропадает информация о том, как структурирован текст, все одинаково употребляется веско больше данных.
- Модель умышленно натренирована на нахождение вхождения НЕ слов и биграмм 1-го запроса.
- Анализируется «важный» контент странички («Королев») . А какая часть странички и контента является главной – знаменито лишь нейросетям Яндекса.
Поиск продвинулся на 1 шаг: сейчас не пропадает информация о словах, не содержащихся в запросе. Но это еще не Natural Language Processing (NLP) .
Как это смотрится. На данный момент теснее до 40% всех запросов неповторимы, другими словами не повторяются желая бы дважды в течение всего периода наблюдений. Пример входных данных:
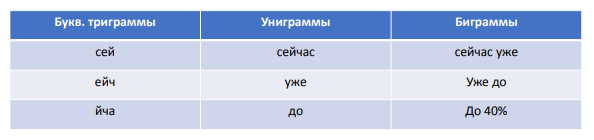
В анализ идут буквенные триграммы (часть слова) , униграммы (1 слово) , биграммы (2 слова, идущих подряд) .
Как это смотрится в поиске. К примеру, вводим не чрезвычайно частотный запрос, раскрывается картина, которую SEO-специалисты в высококонкурентных темах созидать не привыкли:
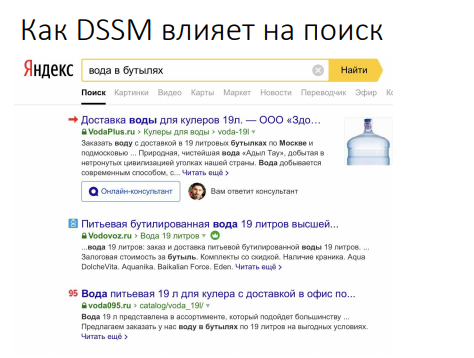
В запросе содержится слово «бутыль», а в выдаче «бутилированный» и «бутылка» – это не совершенно синонимы. Но имеются повторяющиеся паттерны в title, которые можнож выделять зрительно или автоматом и использовать.
По словам Алексея, были случаи, когда прибавление всего 1-го слова в title, не содержащегося в запросе не являющегося синонимом, дозволяло (на «Палехе») вытаскивать запросы из ТОП 15 в ТОП 3. Метод анонсировали издавна, но работать он начал лишь в зимний период 2018–2019 года.
Как с сиим работать. Используем методику автоматического выделения. Берем выдачу «доставка воды москва» и выделяем определенные текстовые паттерны, используя методы, которые определяют тематическую близость. Получаем биграммы, которые в запросе вообщем не содержатся.

Практика указывает, что добавление в title, тексты и иной контент странички слов, не содержащихся в запросе, но релевантных теме, позитивно сказывается на ранжировании.
Как «Палех»/«Королев» влияют на оптимизацию
Поменялись сортировки. Кто продвигает под Яндекс, знает, что сортировки слов – это самое главное при работе с контентом. Ежели ошибся на шаге сортировки, то остальное можнож не улучшить. Поменять что-либо фактически невероятно.

- Стало меньше схожих слов в запросах 1-го кластера. Ранее такового разброса в конкурентных(!) темах не было.
- Больше кластеры, больше НЧ на страничке.
- Еще труднее стало деоптимизировать страничку. Ежели запрос повело не туда, ранее необходимо было просто убрать ключевые слова. А сейчас, так как поиск оперирует словами, которые не соединены с ключевиком, деоптимизировать стало вообщем трудно, проще смириться с сиим.
Это главный момент, который поменял регламент по оптимизации.
Что такое BERT
Это последующий шаг по сопоставлению с «Палехом»/«Королевом». Метод BERT от Google был анонсирован в 2018 году, запущен в октябре 2019. Пока обхватывает лишь британский язык и 10% запросов.
- BERT – Bidirectional Encoder Representations from Transformers Bidirectional – метод «читает» текст как слева-направо, так и справа-налево.
- Пробует «угадать» слово по контексту.
- Имеет великое число применений (Q/A, проверка гипотез) . Ежели «Палех»/«Королев» – это просто соответствие запроса документу, то BERT может из кусочка текста, где содержится ответ, выделить сам ответ. Или может проверить догадку и т.д.

Кроме самого токена (вхождения) , BERT употребляет сектор (предложение) и безусловную позицию, которая выходит за рамки сектора.
Этот метод теснее вполне употребляет всю информацию, которая есть в тексте. Учитывает не совершенно лишь все слова, не содержащиеся в запросе, но и дозволяет не утрачивать информацию о расположении слов.
Тем не наименее для решения задачки Q/A ему надобно заблаговременно отдать ответ на этот вопросец в тексте. Сам его составить он пока не может.
Это еще не Natural Language Processing (понимание текста) . Как воздействует BERT на поиск и как под него улучшить?«Пока неизвестно», – заключил Алексей.
Презентацию доклада Алексея Чекушина вы найдете по ссылке
Занимательное с Optimization 2019:
1. Оплошности текстовых анализаторов
2. Как создать контент-стратегию для SEO и пиара за 9 шагов
3. 5 трендов поискового маркетинга от Сайруса Шепарда
4. Современные трудности SEO-специалистов
5. SEO-тренды: как пробиться в ТОП в 2020 году
6. Исследование причин ранжирования в Яндексе и Google в 2019 году
7. Что можнож использовать в Руинтернете из английского SEO
Статьи
Комментариев 0