Обыкновенные и действенные методы выявления вероятности выхода запроса в ТОП | SEO кейсы: социалки, реклама, инструкция
Статья подготовлена на базе выступления на SEO Conference 2017
Большая часть клиентов не готовы ожидать отдачи от продвижения много месяцев. Потому прыткое получение первых результатов – одна из приоритетных задач как для SEO-агентств, так и для штатных профессионалов.
Мы решаем эту задачку, делая упор в 1-ые месяцы работы на запросах с достаточной репутациею и высочайшей вероятностью выхода в ТОП.
Проверим гипотезы
Для опыта брали чуток больше 100 тыщ «грязных» запросов, используя базы поисковых слов, SpyWords, Serpstat, подсказки, статистику Директа и AdWords и иные. Спарсили запросы, соединили в одну таблицу и поставили задачку их оценить.
Существует такое понятие, как Keyword Effectiveness Index(KEI). Это коэффициент эффективности запроса.
Что в нем традиционно учитывается:
- Количество документов в ПС Яндекс, а конкретно количество фактических документов соперников.
- Количество главных страничек в ПС Яндекс.
- Вхождения в основные заглавия.
- Ссылки.
- тИЦы.
- Возраст и так дальше.
Для проверки этих и иных причин мы написали скрипт, в который на вход подается:
- список запросов,
- регион,
- списки схожих и непохожих сайтов-конкурентов.
Также сделали возможность подать произвольные характеристики доменов соперников: например, возраст, количество документов в индексе.
На выходе получаем:
- Рейтинг похожести ТОПа. Он указывает, как много в ТОПе по каждому запросу страничек, схожих на наш сайт и сколько отличающихся
- Медианное значение тех случайных характеристик по ТОПам, которые мы подгрузили на вход.
Чтоб проверить догадку, необходимо рассчитать корреляцию и понять, как работает тот либо другой фактор. Мы тестировали различные варианты, в итоге идиентично превосходно себя проявили две корреляции:
?С текущей позиции сайта. Мы берем случайный сайт, не зная историю позиций, и глядим, по каким запросам он в ТОПе. И глядим корреляцию выросших запросов с каждым фактором.
?С ростом позиций. Мы берем позицию сайта годом ранее либо полгода назад, позицию в истинный момент. И так же сопоставляем с факторами.
Чтоб иметь возможность применять больше данных, в опыте мы употребляли корреляцию с текущей позицией.
Для оценки брали причины:
- Количество документов в ПС Яндекс [KEY]
- Sumantra Roy Key
- Количество главных страничек в ПС Яндекс [KEY]
- Ссылающиеся домены по LinkPad
- Бэклинки по MI
- Количество вхождений в заглавия в ПС Яндекс [KEY]
- Возраст конкурентов
- тИЦ конкурентов
- тИЦ по схожим конкурентам
- Majestic CF
- Количество страничек в индексе Яндекса у конкурентов
- Траф с органики по MI(схожие)
- Рейтинг Alexa
- Похожесть
Расскажу о каждом подробнее.
Количество документов в ПС Яндекс — это довольно занимательный параметр, потому что он возник в расчете KEI от Sumantra Roy больше 15 годов назад. На тот момент это было более либо наименее корректно, потому что в Google по фактически всем запросам документов было не настолько не мало, и цифра была адекватная.
Яндекс же на данный момент эту цифру выдает в 10-ках миллионов, вследствие чего же невероятно оценить, как реально конкурентноспособный запрос благодаря чему фактору. В итоге опыта мы получаем обратную корреляцию: чем больше соперничающих документов, тем лучше для нас, что в принципе неправильная история, которую никак нельзя применять для оценки запросов. Формулу Sumantra Roy чрезвычайно фактически все употребляют по умолчанию. Но она ошибочно работает, потому ее необходимо поменять.
Вывод: Не подходит
Sumantra Roy KEI — средняя корреляция сочиняет фактически 0%, другими словами никак не коррелирует с вероятностью выхода запроса.
Вывод: Не подходит
Количество главных страничек в ПС Яндекс.
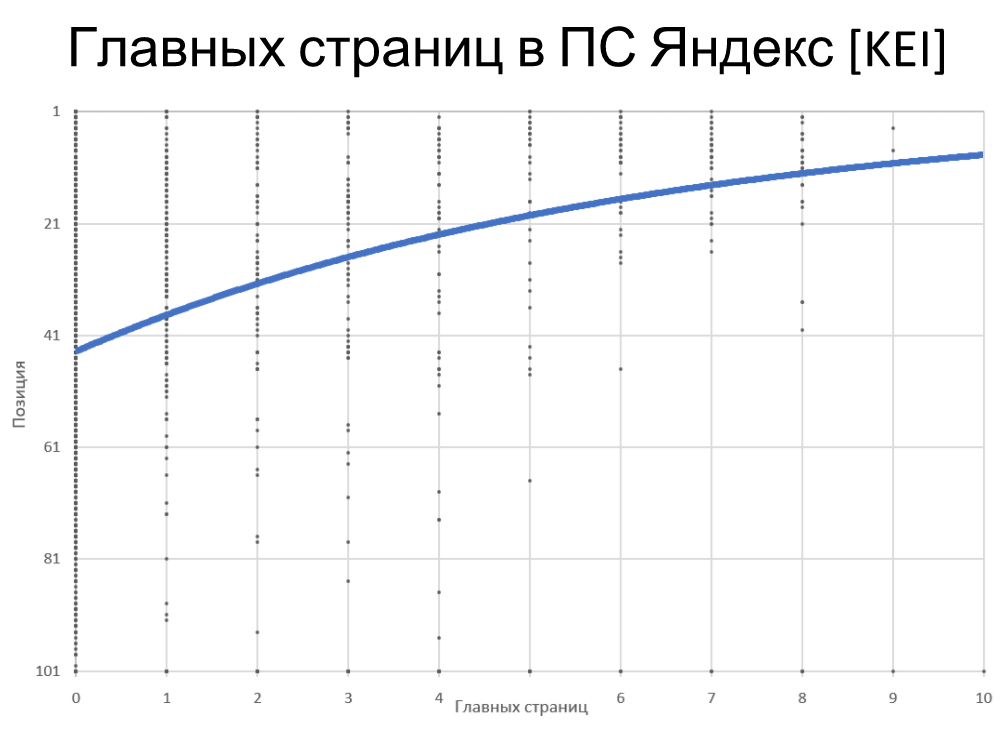
Линия трендов на скриншоте коррелирует с точками. Точки — значения. По горизонтальной оси — это количество главных страничек в ТОПе, по вертикали — позиция. Мы видим, что чем больше главных страничек в ТОПе — тем позиция выше.
Так происходит потому, что этот фактор больше коррелирует с «коммерческостью» запроса. Чем более коммерческий запрос, тем выше возможность выхода главных страничек. Соответственно, продвигая коммерческий сайт, нам еще проще продвинуться по коммерческому запросу. Корреляция довольно мощная — плюс 11%. Чем больше морд в ТОПе, тем лучше для нас. Но нам вновь же это никак не подсобляет, и указанный фактор мы отбрасываем.
Вывод: Не подходит
Ссылающиеся домены по LinkPad.
Средняя корреляция +5%, другими словами чем больше ссылок на соперников, тем ужаснее для нас. Все разумно, но корреляция довольно низкая. Соединено это и с тем, что у LinkPad на данный момент слабенькая база, недостаточно актуальна в сопоставлении с иными.
Вывод: Лучше не использовать
Бэклинки по Megaindex. Ситуация подобная, но тут мы собирали не ссылающиеся домены, а все ссылки.
Корреляция довольно слабенькая — минус 4%.
Чем больше ссылок для соперников, тем ужаснее для нас.
Вывод: Лучше не использовать
Вхождения в заглавия в ПС Яндекс. Средняя корреляция — минус 6%. Чем больше вхождений в заглавия страничек соперников, тем ужаснее для нас. Но это теснее лучше, чем прошлые характеристики.
Возраст соперников. Средняя корреляция — минус 11%. Чем больше возраст соперников, тем ужаснее для нас. Фактически все употребляют этот параметр и верно делают.
Вывод: Можнож использовать
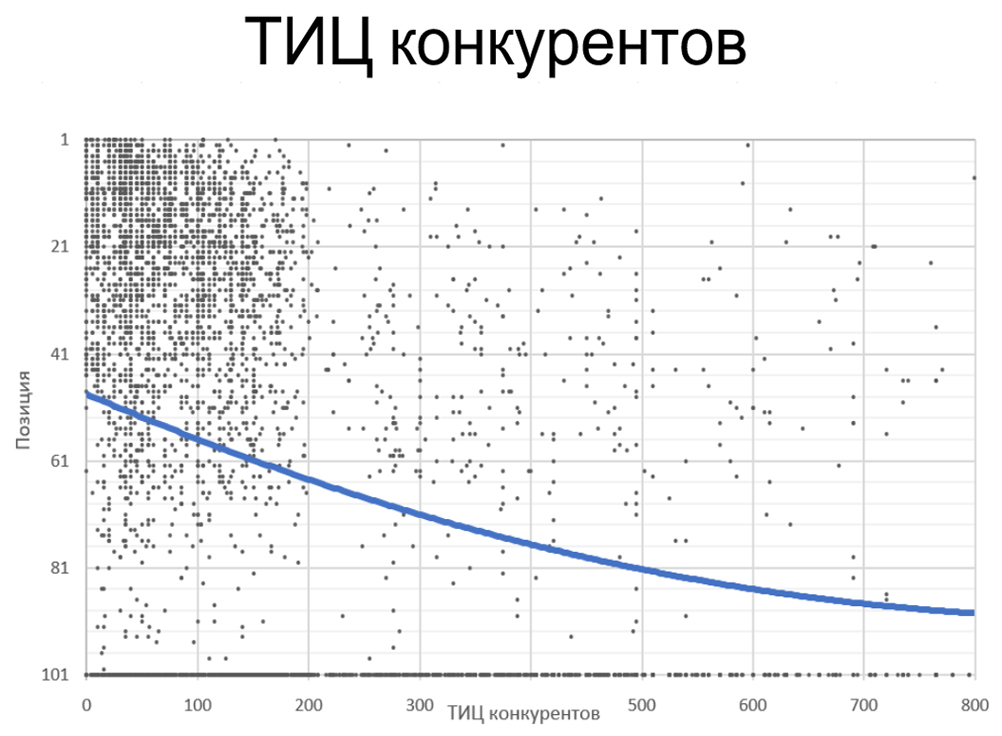
тИЦ соперников. На графике видим, что распределение по ТИЦ довольно равномерное, корреляция низкая — минус 5%.
Чем больше ТИЦ соперников, тем ужаснее для нас.
Вывод: Лучше не использовать
тИЦ по схожим соперникам. В процессе исследования мы расценивали сайты соперников, схожие и непохожие на нас. Через это получили возможность сопоставлять и характеристики не совершенно лишь по всей выборке, а лишь по схожим сайтам. В данном варианте ТИЦ по схожим сайтам зарекомендовал приметно лучше, чем общий ТИЦ.
Средняя корреляция составила минус 15%.
Чем больше ТИЦ у схожих страничек соперников, тем ужаснее для нас.
Вывод: Можнож использовать
Majestic CF. Мы брали CF и TF. ТF зарекомендовал не чрезвычайно превосходно, СF — непревзойденно!
Средняя корреляция: минус 14%.
Чем больше СF у страничек соперников, тем ужаснее для нас.
Вывод: Можнож использовать
Странички в индексе Яндекса у соперников.
Средняя корреляция минус 14%.
Чем больше страничек в индексе соперников, тем ужаснее для нас.
Вывод: Можнож использовать
Трафик с органики по Megaindex по схожим соперникам.
По непохожим сайтам средняя корреляция – слабенькая, по схожим – заметная, минус 11%.
Чем больше трафик с органики в индексе соперников, тем ужаснее для нас.
Вывод: Можнож использовать
Рейтинг Alexa. Мы осмотрели некие трафиковые характеристики, превосходно себя показал Alexa, желая для Рф его релевантность нам не совершенно понятна. Но в итоге параметр превосходно работает под оценку для Яндекса. Средняя корреляция — минус 12%. У всех страничек отрицательная. Чем лучше рейтинг Alexa соперников и выше трафик, тем ужаснее для нас.
Вывод: Можнож использовать
Дальше мы перешли к тем характеристикам, которые, фактически никто не употребляет в собственной оценке.
Схожие соперники в ТОПе
На скриншоте график зависимости числа схожих документов в ТОП 20 и позиции.
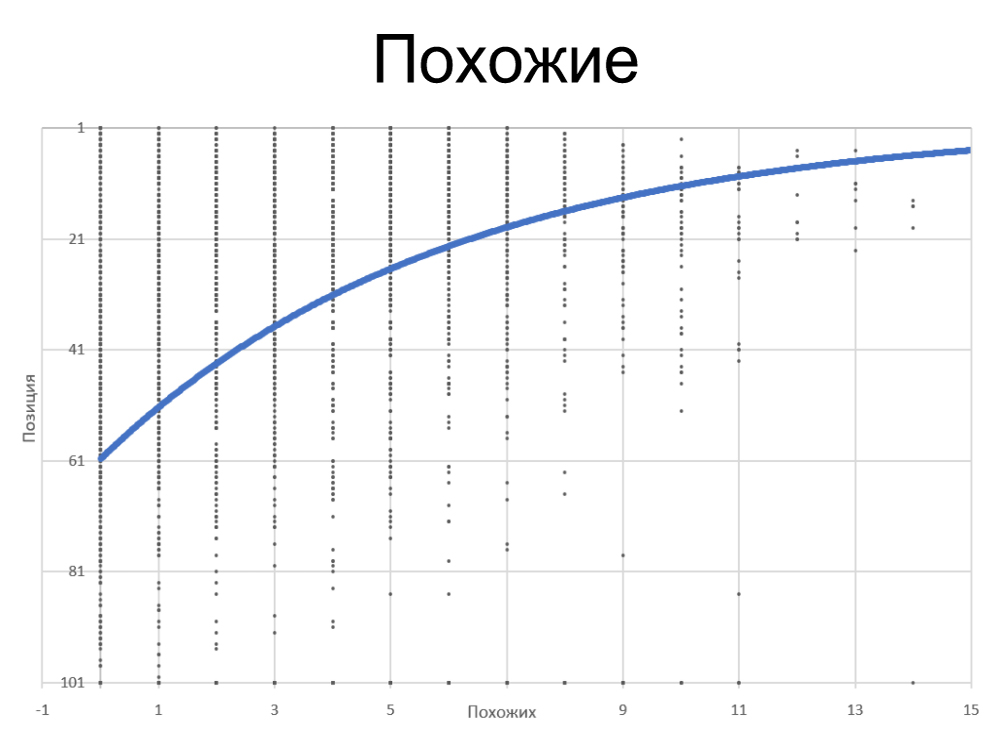
Соответственно, чем больше схожих на наш страничек, тем выше наша позиция. Мы видим, что при великом количестве схожих страничек фактически нет запросов ниже 20 позиции, все в ТОПе. Средняя корреляция +25%.
Это больше, чем хоть какой из других характеристик.
Чем больше схожих страничек в ТОПе, тем лучше для нас.
Вывод: Необходимо применять обязательно
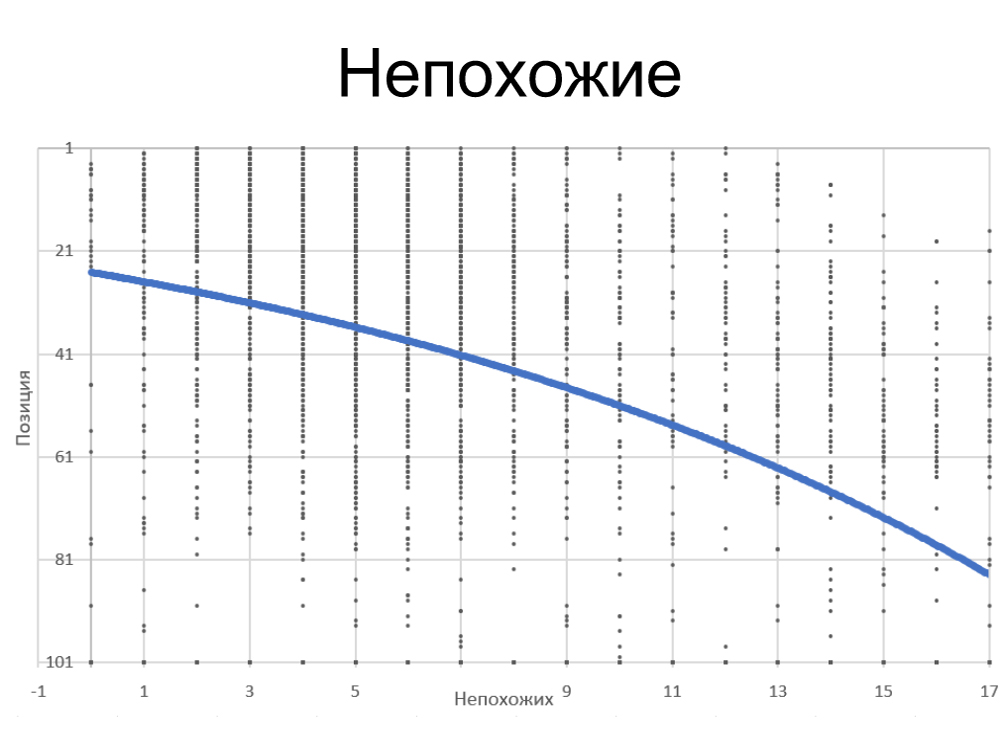
Схожие соперники в ТОПе
Сходственно работает фактор по непохожим сайтам. Чем больше непохожих страничек, тем выше наша позиция. Средняя корреляция минус 17%.
Чем больше непохожих страничек в ТОПе, тем ужаснее для нас.
Вывод: Необходимо использовать
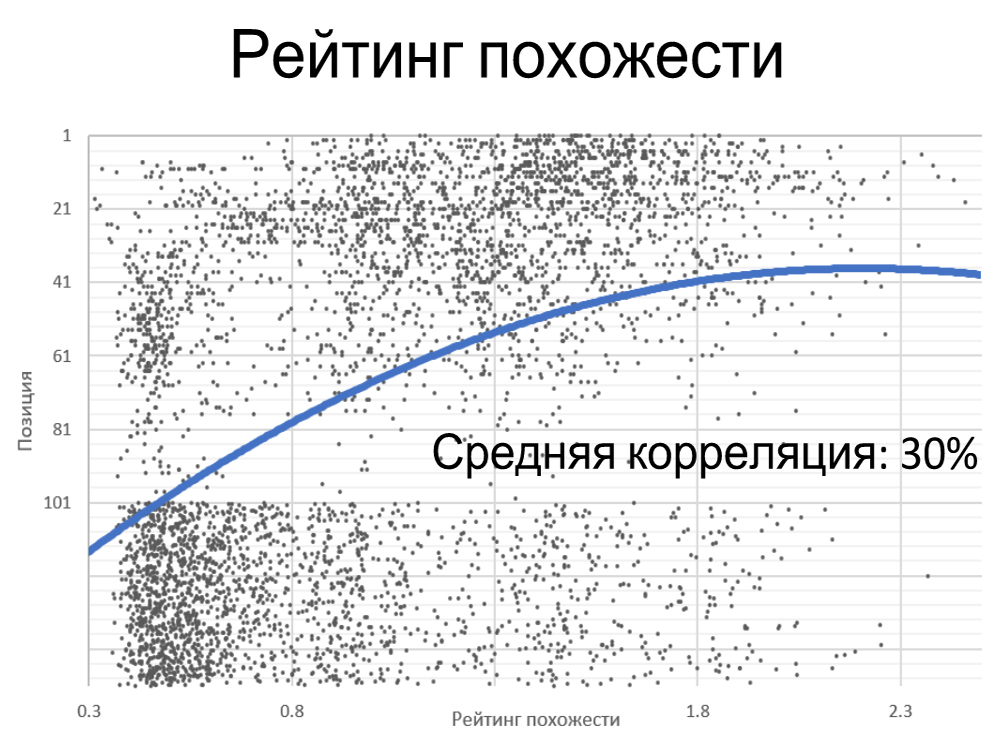
Рейтинг похожести.
Обратим внимание на рейтинг похожести. На скриншоте видно скопление значений в нижней доли графика там, где индекс похожести маленький и в верхней доли – где он высочайший.
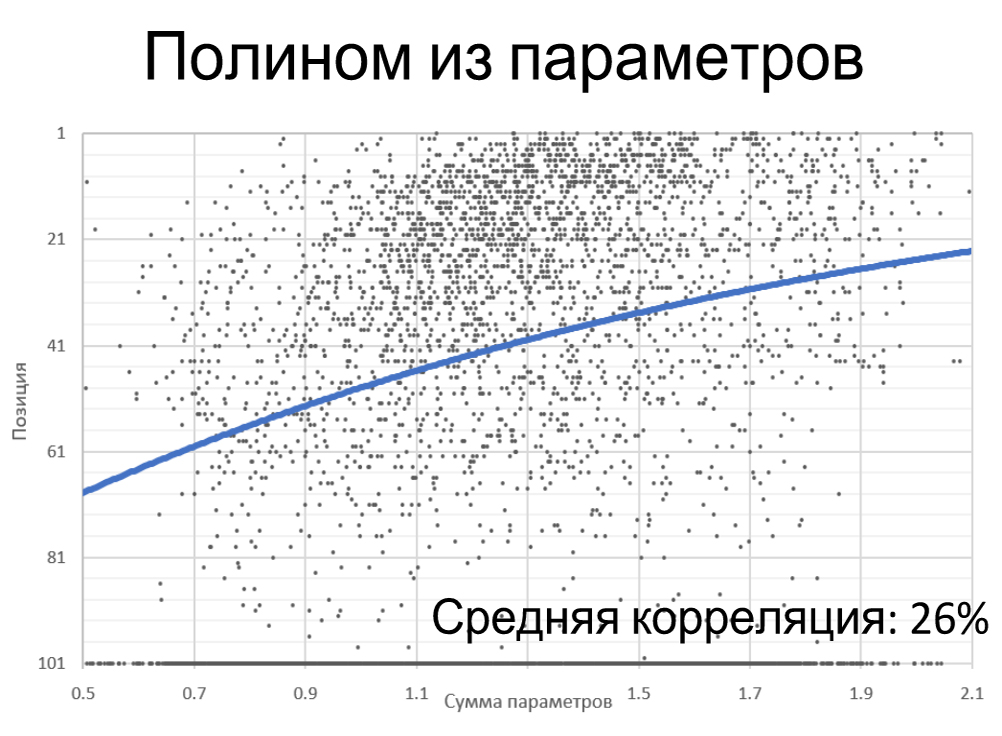
Сумма характеристик(не считая похожести).
Дальше мы сложили все означаемые характеристики из этого исследования, не считая похожести. Вновь же видим, что при низкой сумме всех характеристик лучшые позиции фактически отсутствуют, преобладают низкие.
При высочайшем рейтинге количество запросов в ТОПе растет. Тут не так ясно это видно по скоплению значений, но видно, ежели поглядеть на запросы в ТОП 10 и по полосы тренда.
Средняя корреляция — плюс 26%.
Чем выше суммарный рейтинг по сумме характеристик, тем лучше для нас.
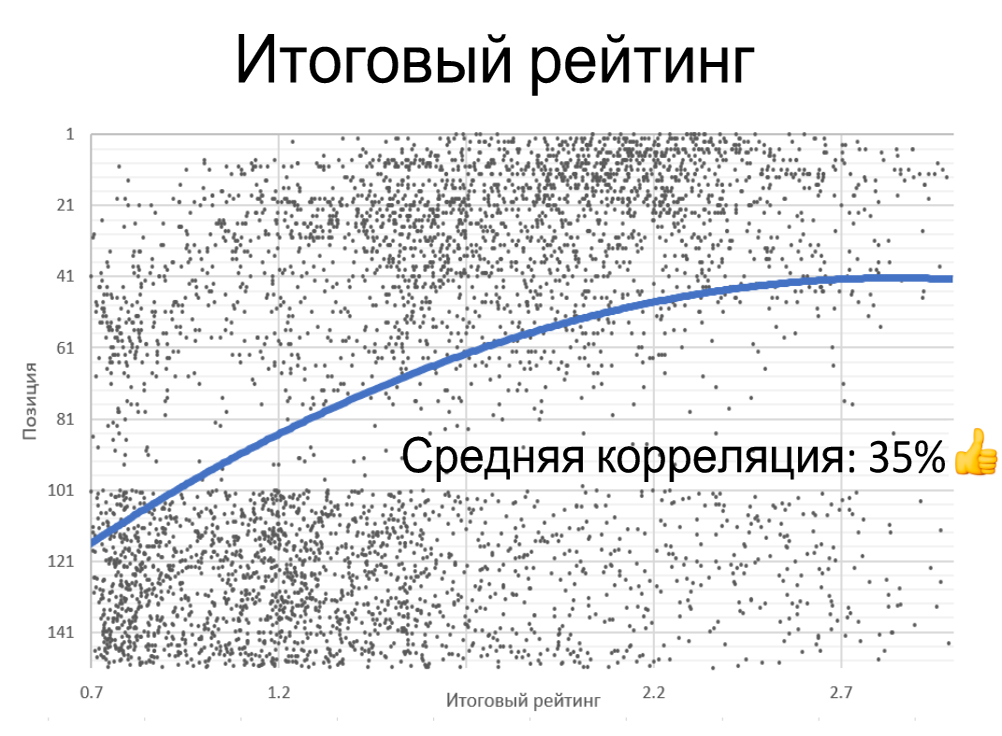
Итоговый рейтинг
В нем мы собрали все характеристики совместно с «рейтингом похожести».
При низком итоговом рейтинге глядим скопления низких характеристик, лучшые позиции растут при высочайшем суммарном рейтинге. Средняя корреляция — 35%.
Проверим скорость работы с учетом похожести
Эта методика превосходно работает как на оценку маленький группы запросов, так и на прыткую фильтрацию перечня на 10-ки и сотки тыщ запросов.
В тестировании употребляли несколько сервисов: SerpStat, SpyWords, Букварикс и Муравейник tools.
Serpstat. По медли затратили 4 минутки, получили 4300 запросов главных соперников.
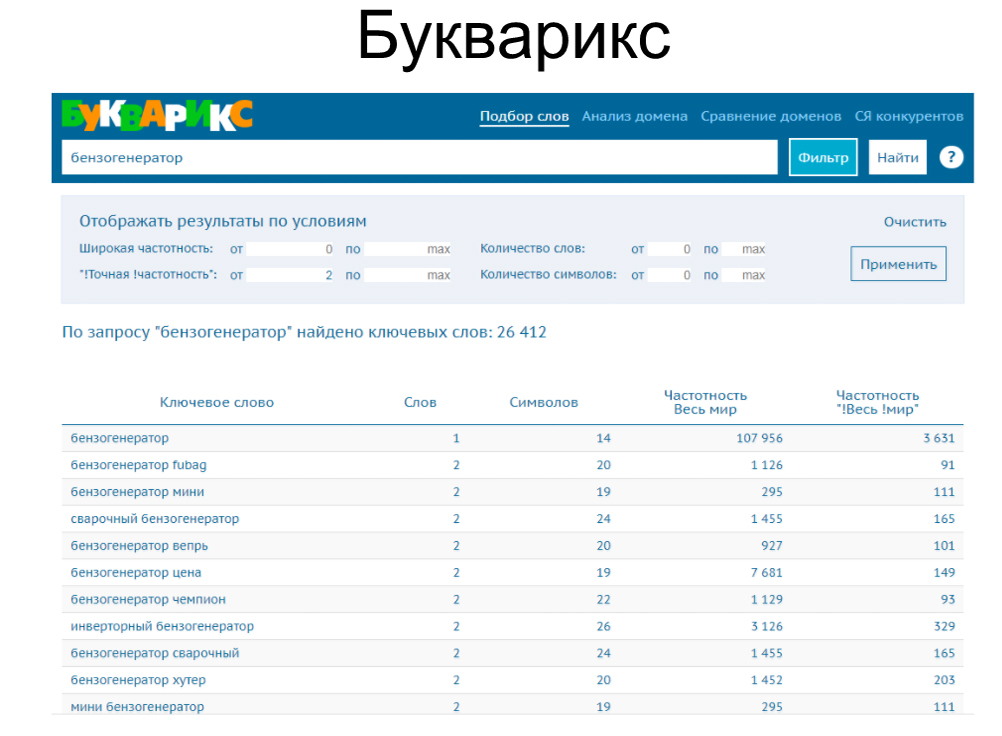
Букварикс. Собрали 75 000 запросов, затратили 7 минут. Запросы старались брать не нулевые, употребляли фильтр от 2 и более четкой частоты.
SpyWоrds. Затратили 4 минутки, собрали 20 000 запросов.
В KeyCollector отсеяли запросы с низкой частотой. Фактически половина запросов отсеялась, осталось мене 55 000.
Затратили 2 минутки вручную, и 1 час работал сервис.
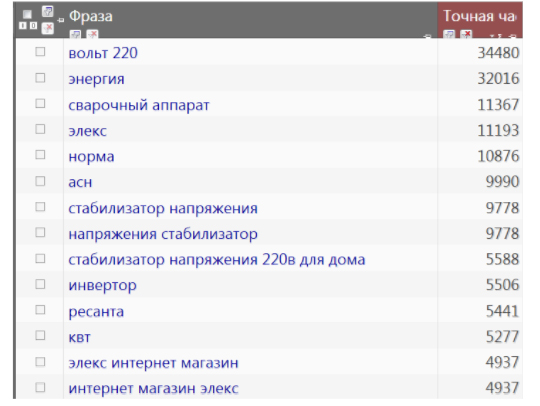
Муравейник Tools. На вход подали перечень запросов. Оценили несколько страничек соперников как похожие/непохожие. Выгрузили итоговую таблицу.
Получили итог в виде перечня данных. Сортируя таблицу по рейтингу, мы видим пригодные нам запросы, в ТОП 20 входит чрезвычайно много схожих страничек, непохожие отсутствуют. Дальше мы исключаем запросы с низким рейтингом. Ежели обретаем запросы с высочайшим рейтингом, но не видим тут позиции нашего сайта, мы отыскиваем предпосылки, почему так. Фактически всегда оказывается, что на страничке отсутствует эта ключевая фраза. Прибавляем, и фактически всегда запрос резко растёт.
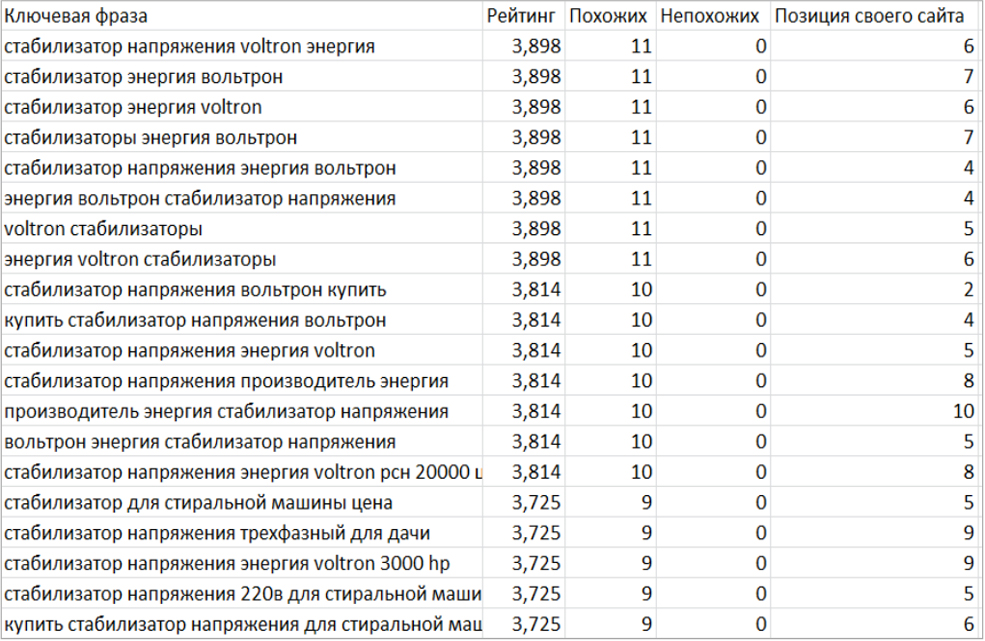
Итог занял 90 минут работы автомата, и лишь 27 минут истратили на ручную работу. Отфильтровано 43 000 запросов по частоте, 47 000 запросов по похожести. На выходе получили чистую семантику на 7500 фраз. Ручная чистка без автоанализа похожести заняла бы не меньше 5 часов(плюс такое же время автосъема частот в KeyCollector).
Что еще можнож сделать?
Можнож выгрузить перечень соперников и смонтировать по нему иные характеристики, которые в исследовании проявили себя как полезные.
Для этого можнож применять A-parser, CheckTrust, RDS API и аналоги.
Так смотрится итоговая таблица(пока без подгрузки кластеризации):
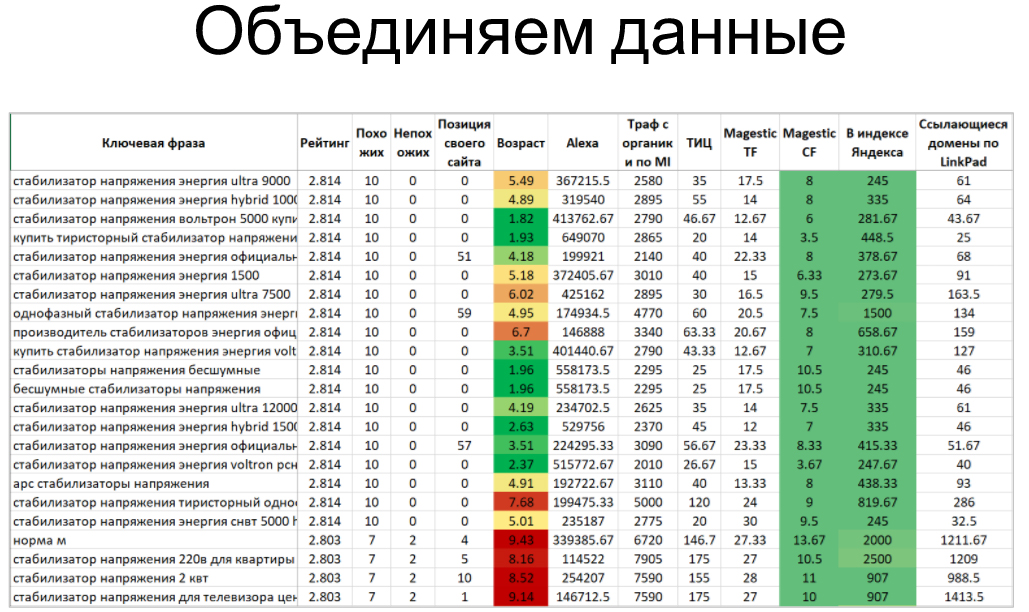
Когда у вас 200 запросов на продвижении, вы вручную сможете проверить все запросы. Но когда к вам прибывает на продвижение великий интернет-магазин, у которого 20 000 запросов, без сходственного анализа вы будете расходовать время на работы по запросам, которые никогда не продвинутся.
Дальше все объединяется с кластеризацией, и вы сходу видите возможность выхода по запросу каждого кластера. Делаете упор на более вероятных кластерах и получаете отдачу от продвижение еще прытче и заметнее.
Фуррора вам в продвижении собственных и клиентских проектов.
Комментариев 0