Как беречь данные по оптимизации сайта: сводная таблица | SEO кейсы: социалки, реклама, инструкция
В обсуждении с сотрудниками из иных компаний был поднят вопросец, о том, как комфортно беречь данные по оптимизации сайта(семантическое ядро, метатеги, данные по ТЗ и их внедрению и т.п.). Я предложил свое решение данной задачки, которое мне кажется более комфортным для работы и восприятия.
Я именую это решение «Сводная таблица оптимизации сайта» — это хабовая таблица, агрегирующая в себе более главные данные, дотрагивающиеся оптимизации сайта и подсобляющая контролировать его продвижение.
О том, какие данные содержатся в данной таблице, расскажу в данной статье.
1. Инструменты
Сходу проговорюсь, что мы работаем в облаке Google Drive и его прибавлениях. Этому есть несколько обстоятельств:
- С проектом работает несколько профессионалов(оптимизатор, проект-менеджер, копирайтеры и т.д.). Работать в облаке веско прытче, чем перекидываться копиями документов по почте.
- Время от времени данные могут потребоваться, когда спец физически находится не у рабочего компа, а телефон либо планшет постоянно под рукою.
- Возможность легкой передвижения данных меж документами.
У нас есть стандартизированная структура, как беречь данные по проектам в Google Drive, чтоб можнож было брать подходящую информацию, не отвлекая иных от работы.
Структура смотрится последующим образом:
- У каждого профессионала есть папка «Проекты».
- Для каждого проекта заводится своя папка с подходящим заглавием.
- Снутри папки проекта есть несколько обычных подпапок и неповторимые папки под потребности проекта.
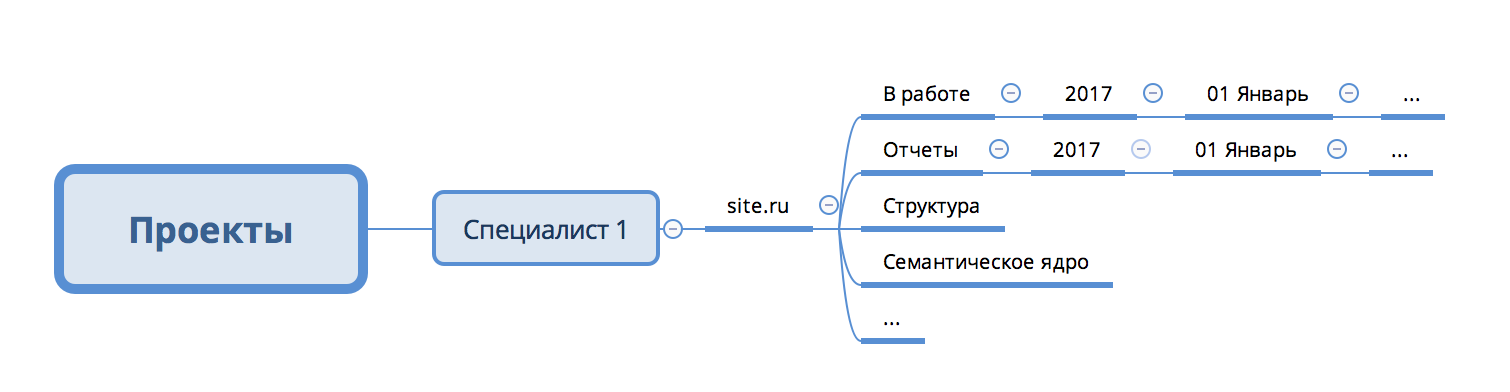
Рис. 1 Структура папки проекта
2. Структура таблицы
Мы сочиняем сводную таблицу сначала работы над проектом и дополняем ее в протяжении всей работы.
Обычные столбцы, используемые в таблице:
- URL — адреса страничек. Данные из столбца также могут употребляться в качестве якоря для функций(ВПР, СУММЕСЛИ и т.п.);
- Структура — место странички в структуре сайта. Аналог классических хлебных крошек;
- Тип — к какому типу относится страничка. Необыкновенно актуально для интернет-магазинов, в каких мы выделяем такие типы, как «Каталог», «Тег», «Фильтр», «Карточка», «Информационная» и «Вспомогательная»;
- H1 — h1 заголовок странички;
- Title — title странички;
- H2 — перечень заголовков h2 для странички;
- Текст — пометка о статусе текста на страничке в формате «Есть», «Нет», «ТЗ»;
- Месяц — когда в заключительный разов производились(в)работы либо планируются проводиться(п)работы над страничкой, в формате “ММ.ГГГГ”
- Семантическое ядро — в столбце выкладывается ссылка на файл, в каком содержится семантическое ядро для подходящего раздела.
Не считая обрисованных столбцов, в зависимости от задачки, таблица дополняется и иными данными, к примеру:
- Запрос — главной запрос для странички;
- Группа столбцов по частотностям запроса — в зависимости от сайта, могут содержаться как классические частотности(Ч, “Ч”, “!Ч”, “[!Ч]”), так и с наложением коэффициента по поисковым системам;
- Группа столбцов сезонности за заключительные 12–24 месяца;
- И иные.
С шаблоном таблицы вы сможете ознакомиться по ссылке.
3. Наполнение первичных данных
Заполнить таблицу первичными данными можнож и руками.
Но данный метод не постоянно лучший, потому мы в собственной работе используем Screaming Frog SEO Spider.
Я буду демонстрировать пример работы, основываясь на содействии с данным прибором.
3.1. Парсим данные с сайта
Перед началом парсинга отключаем все напрасные функции, которые нам не пригодятся(Configuration — Spider):
- Проверку изображений;
- Проверку ресурсов(js, css и swf);
- Проверку наружных исходящих ссылок.
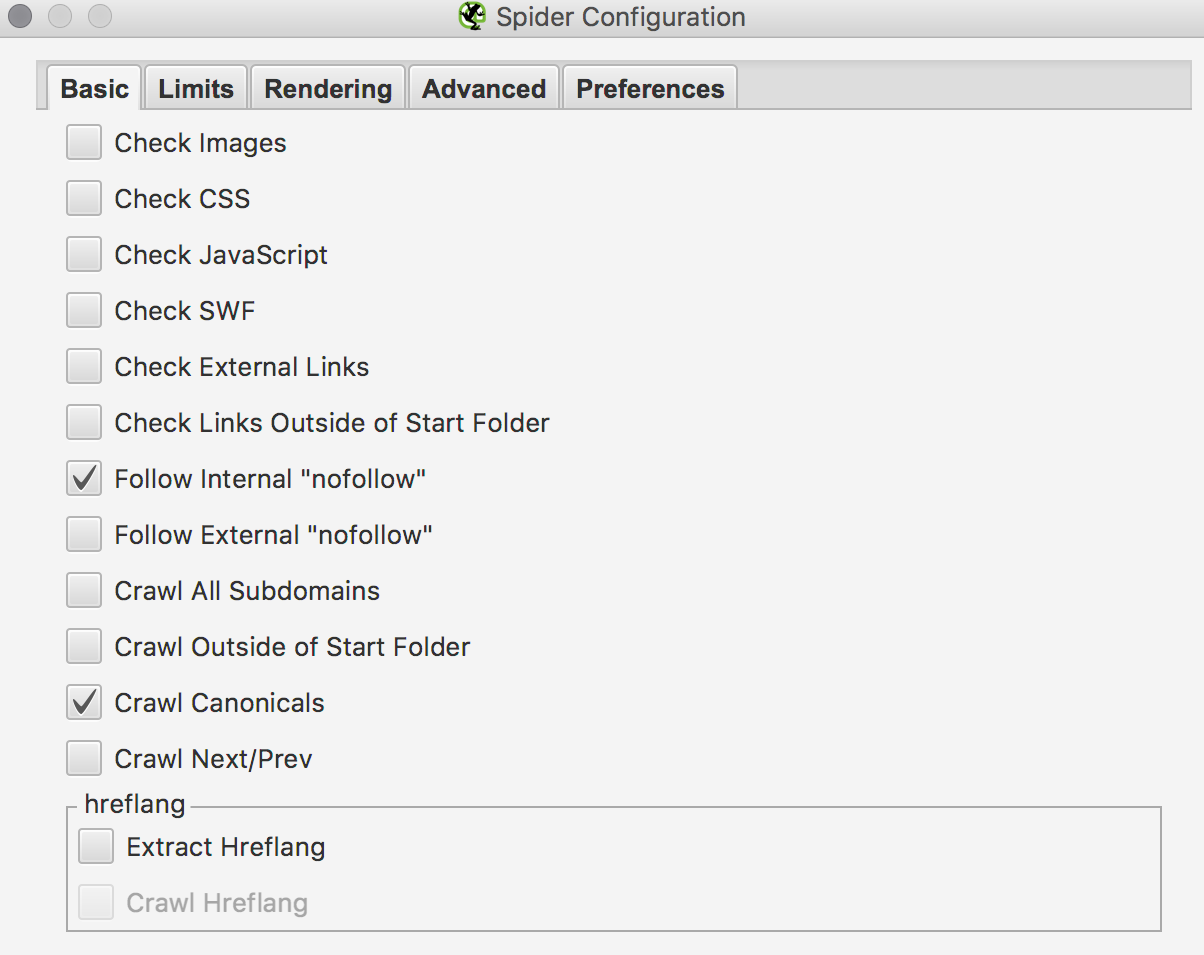
Рис. 2 Настройка Screaming Frog
Дальше копируем XPath корневого блока хлебных крошек на сайте, ежели они там есть.
Для этого:
- Раскрываем внутреннюю страничку, на которой есть хлебные крошки в Google Chrome.
- Раскрываем консоль(Ctrl + Shift + i).
- Выделяем инспектором корневой блок хлебных крошек.
- В контекстном меню избираем Copy XPath.
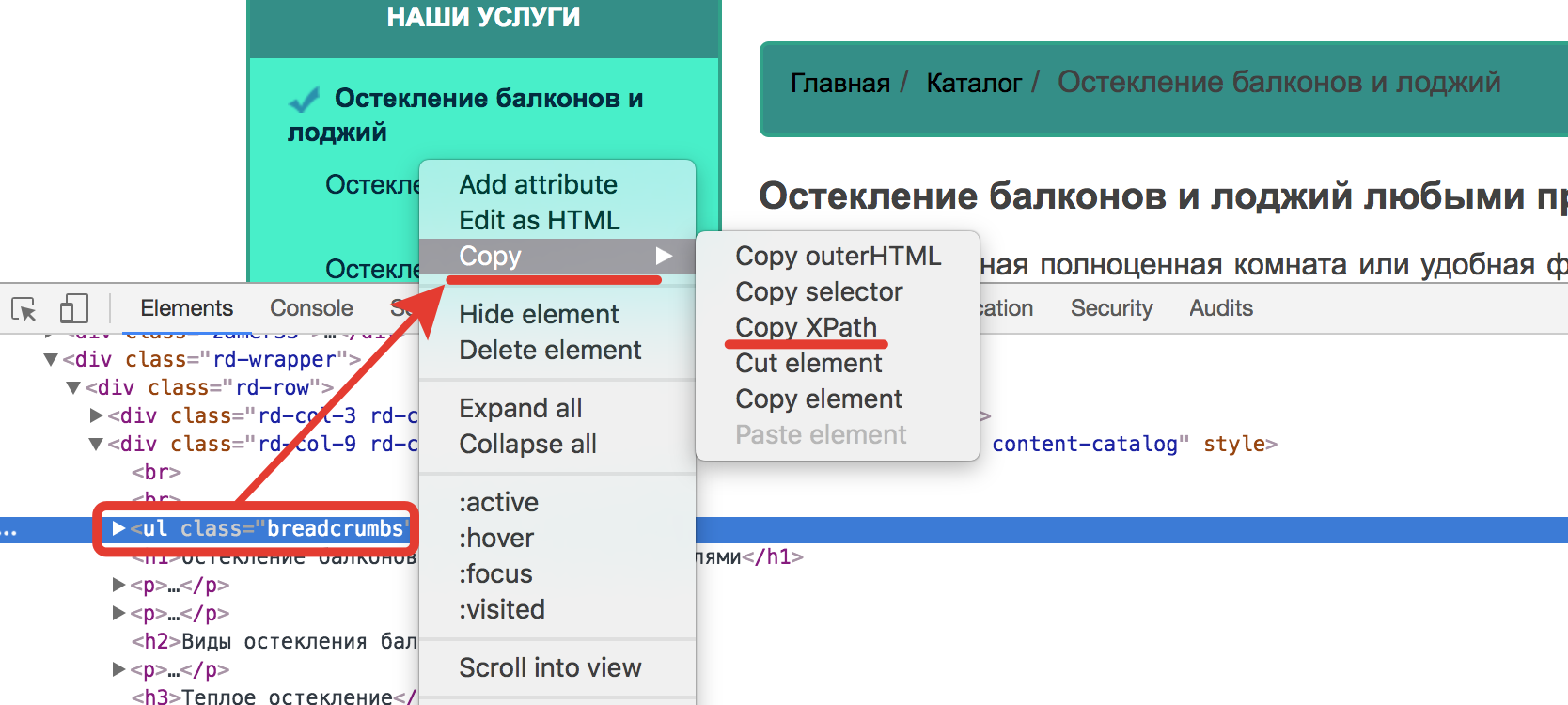
Рис. 3 Копирование XPath
- В Screaming Frog переходим в Configuration — Custom — Extraction.
- В открывшемся окне:
- Избираем XPath
- Вставляем скопированный путь
- Extract Text.

Рис. 4 Extraction в SCSS
И парсим сайт.
3.2. Сведение данных
Опосля того как сайт спарсится, выгружаем отчеты:
- Информация по HTML(Internal — HTML);
- Хлебные крошки(Custom — Exctraction).
И переносим данные отчета в сводную таблицу.
Чтоб не перепутались данные и колонки не «поехали», можнож пользоваться функцией ВПР.
Нас интересуют:
- Url
- H1
- Title
- Хлебные крошки
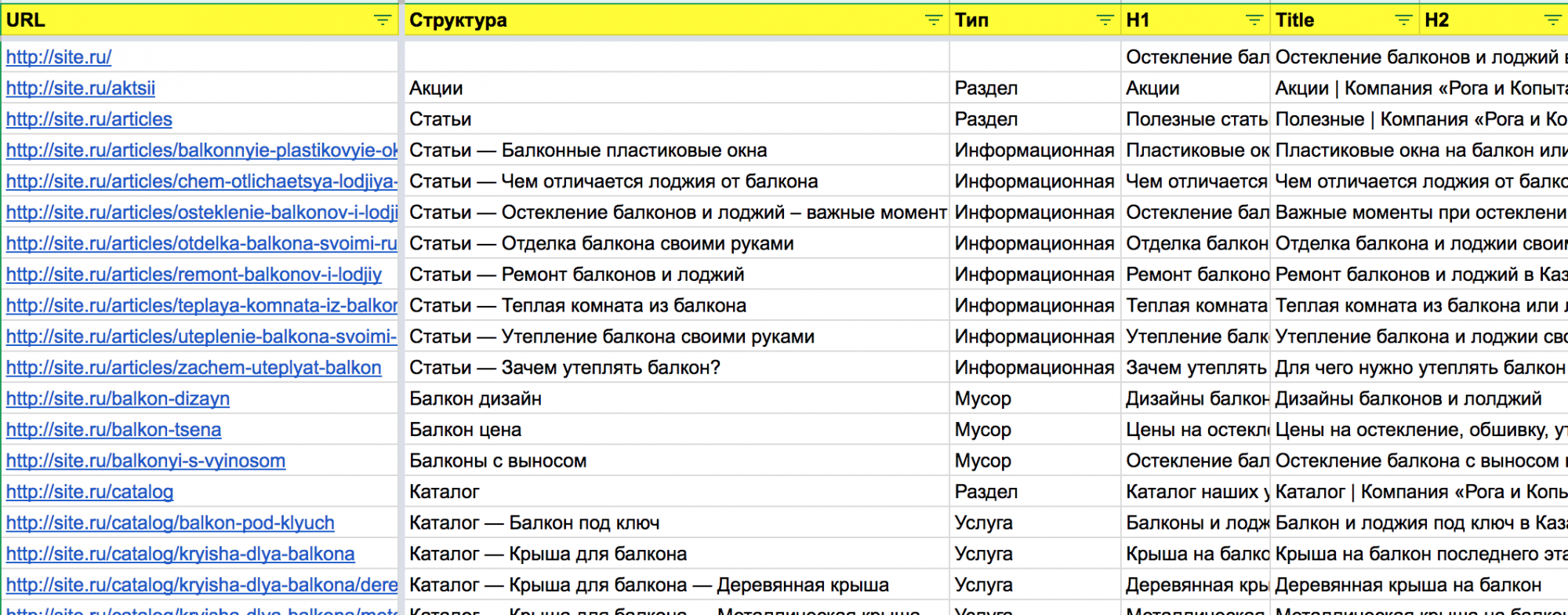
Рис. 5 Заполненная первичными данными таблица
Пример таблицы, заполненной первичными данными по ссылке, на вкладке «Пример».
Метод последующей работы вполне зависит от типа проекта, цели продвижения и выбранной стратегии.
Заключение
Опосля внедрения данного прибора в свою работу мы решили почти все задачки, которые остро стоят перед каждым профессионалом(все метатеги в одном месте, контроль исполнения задач и т.п.).
Полагаюсь, вам сходственная сводная таблица тоже будет полезна.
Ежели у вас есть вопросцы, готов их обсудить.
Комментариев 0