Как убыстрить сбор семантического ядра для B2B | Статьи SEOnews

Суть способа состоит в том, чтоб брать в продвижение лишь те запросы, по которым топ-10 «похож», другими словами состоит из страниц такого же типа, как продвигаемый чертеж. Способ разработан Андреем Буйловым (управляющий студии интернет-маркетинга «Муравейник») .
Я расскажу о собственном опыте внедрения способа на образце ниши «Ножи» для интернет-магазина оборудования для ресторанов и общепита.
Составление семантического ядра
Составление семантического ядра (перечня ключевиков) для интернет-магазина является трудозатратным действием и времязатратным, так как требуется смонтировать и обработать великое число запросов.
Весь процесс сбора семантики можнож поделить на четыре великих шага:
- Сбор маркеров.
- Парсинг запросов.
- Чистка запросов.
- Кластеризация запросов.
Для проектов из сферы B2B необыкновенность сбора семантики содержится в том, чтоб до шага кластеризации исключить поисковые фразы для B2C, тем самым веско уменьшить время. Для этого и подходит способ, который употребляет оценку похожести для приоритизации – выбора тех групп запросов, с которых стоит начать оптимизацию сайта, а какие отложить.
Сбор маркеров
При сборе маркерных запросов я употребляла три группы маркеров:
1. 1-ая группа маркеров с коммерческими словами – «купить нож», «цена нож», «нож интернет-магазин» и т.п.
2. 2-ая группа маркеров с B2B фразами:
( барные|+для баров|+для кафе|+для кондитерских|+для кофейни|+для кофеен|+для магазина|+для общепита|+для сферы публичного питания|+для отелей|+для гостиниц|+для пекарен|+для пиццерии|+для ресторанов|+для столовой|+для кафетерия|+для супермаркетов|+для таверны|+для трактира|+для фастфуда|+для фаст фуда|+для стритфуда|+для стрит фуда|+для бургерных|+для харчевни|+для пищевых производств|+для точек прыткого питания|инвентарь|оснащение|готовые решения|оптовик|оптовый|оптом для бизнеса|оптом и в розницу|оптово розничный|официальный дилер|официальный представитель|официальный дистрибьютор|официальный поставщик|профессиональные|b2b)
3. 3-я группа маркеров по типу – «обвалочный нож», «филейный нож» и т.п.
Парсинг запросов
Этот шаг досконально обрисовывать не буду, перечислю лишь главные приборы и сервисы, которые я использую для сбора маркеров и ключевых фраз:
- Яндекс Wordstat,
- Wordstat Assistant,
- поисковые подсказки Яндекса и Google,
- рекомендованные запросы в Яндекс Вебмастере,
- поисковые запросы в Яндекс Метрике и Google Analytics,
- Screaming Frog SEO Spider,
- Keys.so,
- Rush Analytics,
- Key Collector.
Необходимо отметить, по умолчанию Wordstat дает всего 41 страничку результатов. Чтоб обойти ограничение, я использую способ сбора частотности для запросов данной длины (до 7 слов) .
Для этого прибавляю запросы в сервис Rush Analytics последующим образом (кавычки обязательны) :
«ножи ножи»
«ножи ножики ножи»
«ножи ножики ножи ножи»
и так дальше до 7 слов.
Чистка семантического ядра
Опосля парсинга подсказок и ключевых фраз необходимо удалить все нерелевантные запросы, но делать это вручную чрезвычайно длинно.
Загружаю фразы в Key Collector 4. Через функции «Минус слова», «Анализ групп», «Неявные дубли» убираю нецелевую мусорную семантику. Снимаю частотность и убираю нулевые запросы. Вы это сможете сделать через удачный для вас сервис.
Собираю данные о поисковой выдаче Яндекс и Google:
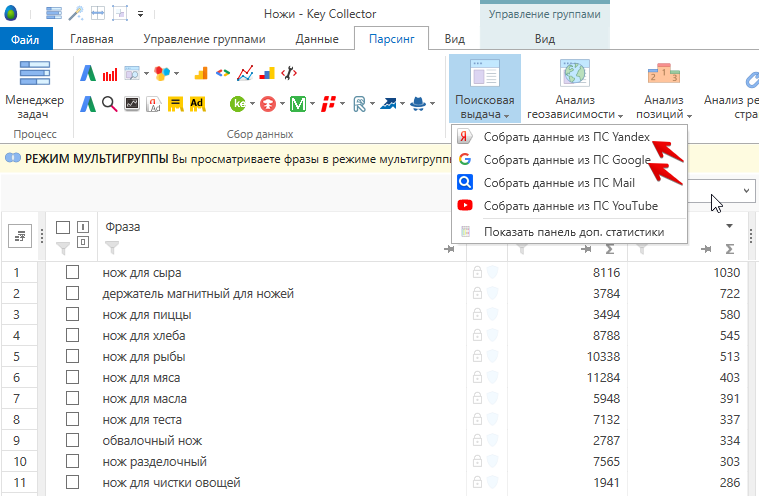
Выгружаю результаты поисковой выдачи Яндекс и Google в отдельные таблицы.
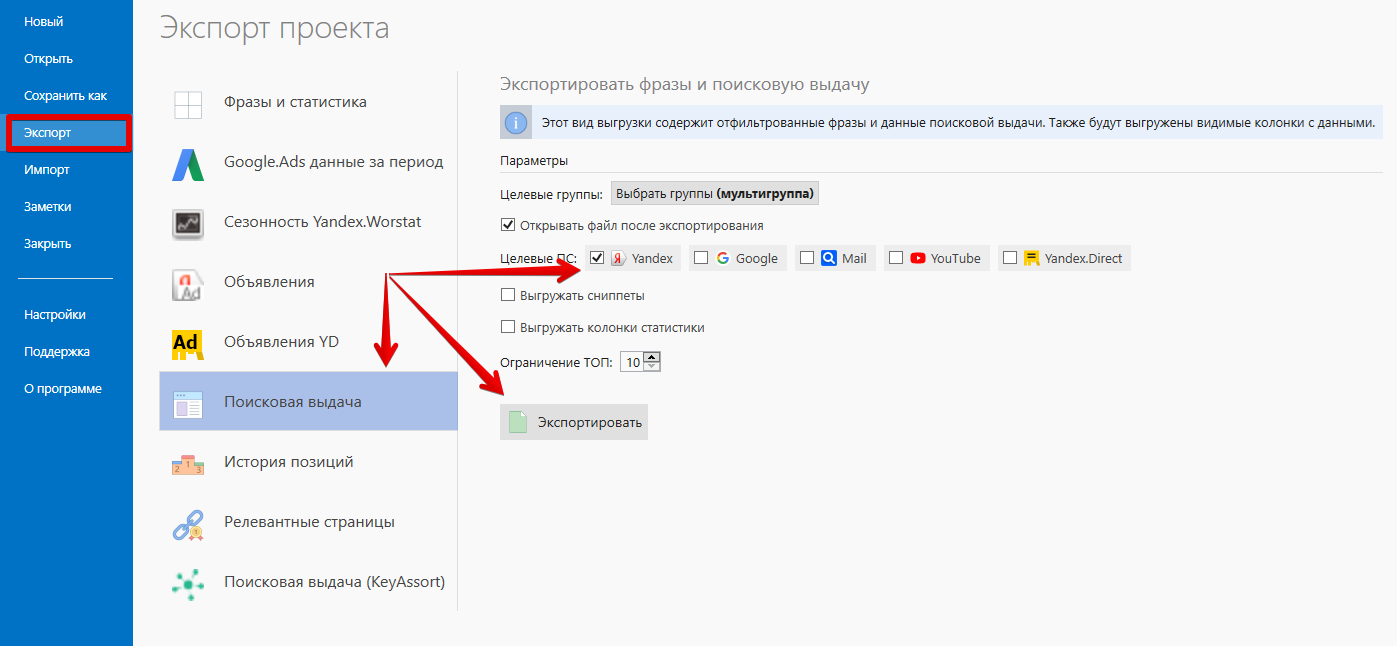
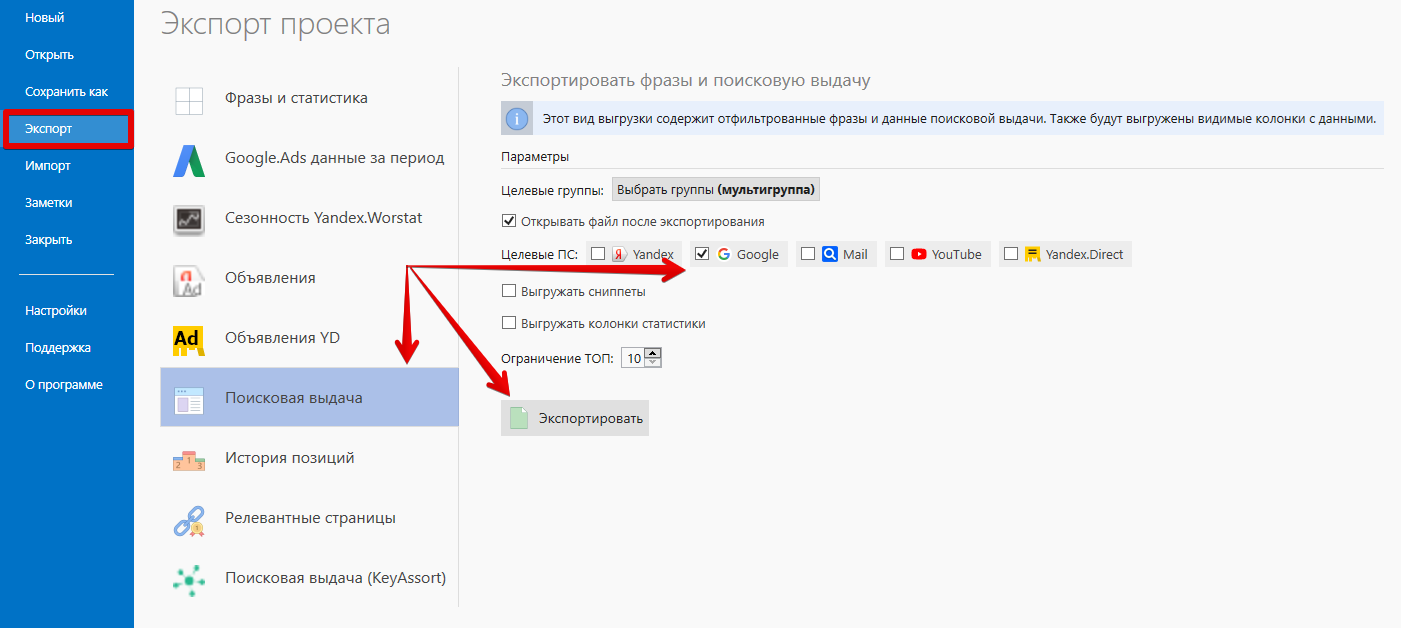
Сейчас переходим к применению методики:
1. Создать копию шаблона в Google Таблицах, перейдя по ссылке.
2. Скопировать все столбцы выгруженной таблицы и вставить во вкладку «KeyCollector» Google Таблицы.
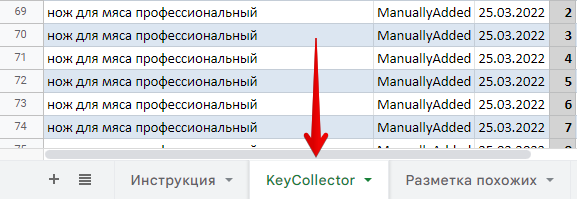
В шаблоне для наглядности имеются данные. Ежели ваших запросов меньше, то удалить негодные строчки. Ежели ваших запросов больше, то протянуть формулы в столбцах с «G» до «J» до конца ваших данных.
Кстати, ежели запросов много и есть трудности переноса данных в Google Таблицу в силу великого количества строк, то я делала так:
- загружала Excel-таблицу на Google Диск, раскрывала через Google Таблицы;
- сохраняла как Google-таблицу;
- и теснее в перевоплощенную таблицу переносила формулы и другие листы из шаблона.
С первого раза может показаться, что тяжело. Но когда следует речь о 10-ках тыщ запросов, применение шаблонов стоит того, чтоб разобраться в вопросце.
3. Переходим во вкладку «Разметка похожих». Это сводная таблица. Чтоб не запутаться, советую поначалу всем доменам в столбце «С» убрать галочки, а в столбце «D» проставить, протянув мышкой.
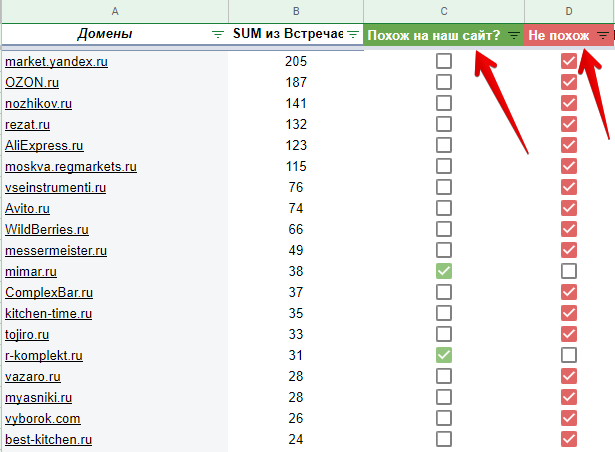
Ежели у вас есть готовый перечень соперников, то сможете, загрузив в новейшую вкладку, через функцию «=ВПР() » отыскать их и отметить галочкой в столбце «C», в столбце «D» убрать галочку.
Дальше пройтись по доменам из столбца «A». Отыскать соперников. Не пренебрегать отметить галочкой в столбце «C», в столбце «D» убрать галочку для страниц, схожих на продвигаемый чертеж.
4. Переходим во вкладку «Итог». Я прибавляю в ячейку «C1» функцию =SORT( A:B;B:B;ЛОЖЬ) , чтоб отсортировать ключевые фразы по убыванию похожести. Дальше копирую и забираю в работу запросы похожестью не наименее 10.
То же самое проделываю для таблицы с данными поисковой выдачи Google.
Соединяю итоги по похожести из Яндекс и Google, удалив дубликаты.
Итоговые запросы из приобретенного перечня загружаем для кластеризации.
Кластеризация запросов
Распределяем схожие запросы по группам.
Я группирую в кластеры через Key Collector 4. Выставляю тип кластеризации «по поисковой выдаче (v.3) », режим сортировки «пересечение», сила сортировки 3 либо 4 в зависимости от количества ключей и частотности.
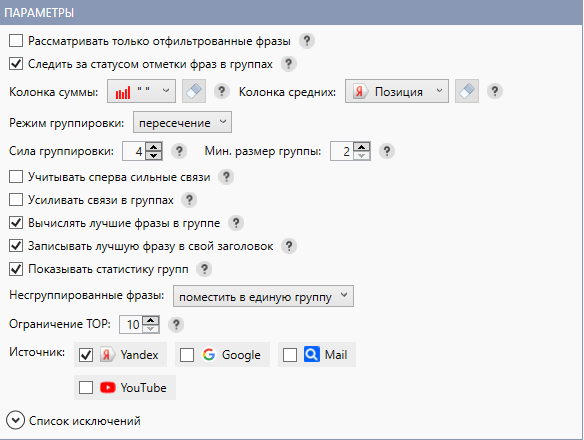
Опосля кластеризации совмещаем группы с посадочными страничками. Готовим технические задания для написания тегов и метатегов, задания на перелинковку и при необходимости для написания, корректировки текстов.
Очевидно, приборов для конструкции и чистки семантического ядра еще больше. И у каждого SEO-специалиста найдутся лайфхаки по работе с семантикой.
В данной статье я поведала о собственном опыте работы с запросами для B2B. Вы сможете поделиться используемыми в собственной работе методиками в комментах.
Статьи
Комментариев 0