Rel=canonical: как можнож и как нельзя канонизировать URL | SEO кейсы: социалки, реклама, инструкция
Представьте ситуацию: поисковой бот прибывает к вам на сайт, сканирует контент и обретает несколько схожих страничек. Как боту выбрать идеальный вариант для ранжирования?
Бот доверится подсказкам, которые вы ему предоставите (ежели лишь вы не будете манипулировать методами поисковика) . Ежели же вы не укажете, какой URL является каноническим (необычным / более главным для вас) , бот сделает выбор за вас. А еще бот может расценить дублирующие странички как идиентично главные. Тогда поисковик истратит краулинговый бюджет на циклический контент, а доходные странички могу в индекс так не попасть.
Как недопустить такового расклада?Ответ может показаться трудным, но в данной статье я объясню все просто. Итак, чтоб бот отобрал в индекс выгодные странички, их необходимо канонизировать.
Читайте ниже, что это означает, как это необходимо не надо делать.
Вы убеждены, что у вас на сайте нет дубликатов?
Канонический URL – это страничка, которую Google принимает как более главную из нескольких дублирующихся URL-ов на сайте. Вероятно вы мыслите: «Я не копирую URL-ы у себя на сайте, потому мне не о чем беспокоиться». На самом деле дубликаты могут быть сделаны автоматом. К примеру, поисковые боты могут зайти на вашу страничку различными методами:
- Через протоколы HTTP и HTTPS:
http://www.yourwebsite.com
https://www.yourwebsite.com
- Через WWW не WWW:
http://example.com
http://www.example.com/
Как лучше попасть к вам на сайт?Выберите лучший метод не пренебрегайте поведать поисковым системам о собственном выборе.
Осмотрим очередной пример, когда множество дубликатов создается на коммерческом сайте автоматом. Сортировка продуктов с поддержкою URL характеристик по размеру, цвету, бренду и т. д. генерирует тыщи дубликатов. К примеру:
- yourwebsite.com/products/girls?category=dresses&color=white
yourwebsite.com/products/girls?category=dresses&color=black
- yourwebsite.com/dress?style=casual,long-sleeve [/b]
yourwebsite.com/dress?style=casual&style=long-sleeve[/b])
Когда бот обретает на сайте фактически схожий контент на различных URL-ах, авторитет сайта/позиция в органическом поиске снижается. Ведь поисковики оценивают неповторимый контент и ранжируют его выше, а дубликаты лишь расходуют их ресурсы. Потому главно хорошим методом разметить, какой контент на вашем сайте неповторимый, а какой нет. В статье я расскажу о 4 методах канонизации страничек. Мы побеседуем о плюсах, минусах и необыкновенностях применения каждого из их.
1. Тег Rel=canonical
Предположим, вы желаете сделать страничку https://yourwesite.com/page.php/ канонической. Для этого добавьте элемент link с атрибутом rel="canonical" и ссылку на каноническую страничку в заголовок head всех дубликатов:
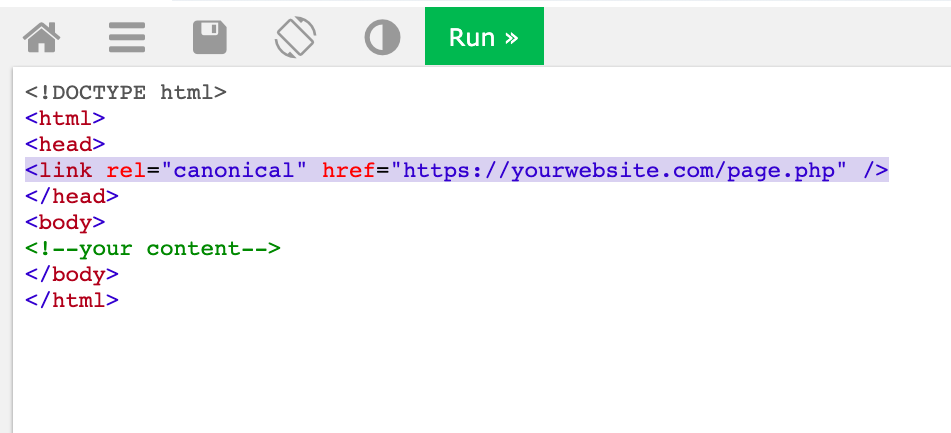
Ежели у канонической странички есть вариант для мобильных устройств, добавьте элемент link с атрибутом rel="alternate" и ссылкой на мобильную версию, к примеру:
link rel="alternate" media="only screen and (max-width: 660px) " href="https://m.yourwesite.com/page.php/"
Элемент link с атрибутом rel="canonical" обязаны содержать безусловный URL (полный) , но не условный (сокращенный) адресок.
2. Rel=canonical HTTP header
Тег Rel=canonical канонизирует HTML-страницы. Для иных же форматов, как, к примеру, PDF, Google советует прописывать атрибут rel=canonical в HTTP-заголовке. PDF на сайте необходимо канонизировать потому, что боты просматривают и индексируют такие файлы так же, как и HTML странички.
Сиим методом можнож пользоваться лишь ежели у вас есть доступ к настройкам сервера. Не буду детально обрисовывать процесс творения rel=canonical HTTP, потому что необходимо углубиться в технические детали, и статья растянется страничек на 10. Оставляю ссылку на превосходную статью от MOZ со всеми аспектами внедрения rel="canonical" HTTP Headers. Так же, как и в rel=canonical link, URL-ы в HTTP-заголовке обязаны быть безусловными.
3. 301 редирект
301 статус код – это перенаправление юзеров и ботов на иной URL.
Когда лучше применить 301 статус код:
- смена домена сайта;
- для оплошности 404 и контента, утратившего актуальность, но имеющего релевантные ссылки и великий трафик;
- для контента, который переехал на иной URL навсегда.
4. Sitemap/Карта сайта
Sitemap, либо по-русски карта сайта — это XML-файл с информацией о местонахождении URL-ов, дате их заключительного обновления, частоте обновления и другие. Вебмастер Google Джон Мюллер подтвердил, что странички в картах сайта бот принимает как приоритетные для индексации и ранжирования.
«...мы используем URL-ы в sitemap как метод понять, какой URL идет считать каноническим для определенного контента».
Все странички в этом файле бот считает каноническими.
Не прибавляйте в Sitemap неканонические странички.
Как делать НЕ нужно
1. НЕ канонизируйте несколько дубликатов различными методами. Предположим, у вас есть странички А и В с схожим контентом. В body странички А вы прибавляете тег rel=canonical, а страничку В указываете в sitemap (подсказываю, что все странички в sitemap бот считает каноническими) . Сейчас бот запутался и истратил время и ресурсы, пытаясь понять, какой контент считать необычным. Не надобно так.
2. НЕ используйте rel=canonical link tag/ HTTP header на страничках категорий продуктов и фильтров. На коммерческих сайтах продукты можнож отсортировать по цвету, размеру, бренду и т.д. Ежели на каждой страничке поставить тег canonical, то бот будет ходить по каждому параметру URL-а и расходовать краулинговый бюджет там. Странички сортировки лучше закрыть в robots.txt либо в meta “noindex”, в зависимости от размера сайта и его специфики.
3. Не используйте robots.txt для канонизации. Директивы в robots.txt демонстрируют, какие страницы/папки необходимо краулить боту, а какие нет. Но вебмастер Google не советует таковым образом канонизировать странички, ведь бот не может даже зайти на страничку и понять, что это дубликат/оригинал.
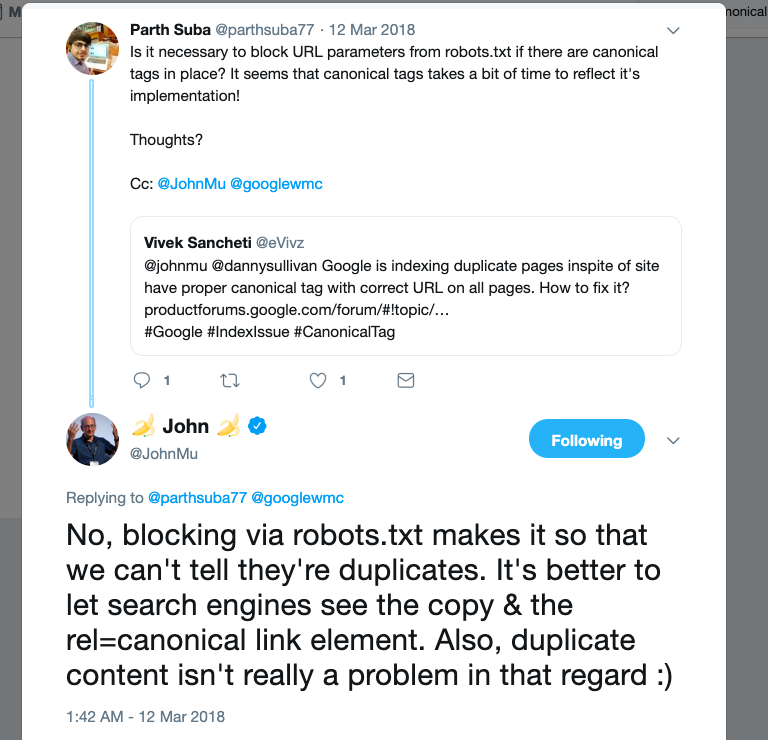
Источник: Twitter
Джон Мюллер:
Блокировка через robots.txt работает так, что мы даже не можем сказать, что это дубликаты. Лучше отдать поисковой системе понять, что дубликаты есть, но ранжировать необходимо страничку с rel=canonical элементом…
4. НЕ линкуйте дубликаты URL-ов снутри вашего сайта. Ежели вы канонизируете страничку, вы считаете ее более главной. Согласитесь, это удивительно, ежели вы ссылаетесь на неканонические/менее главные версии страничек.
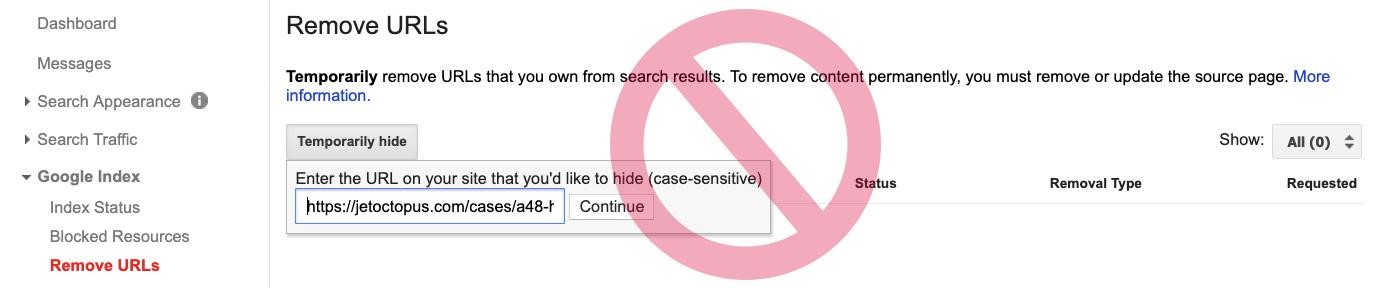
5. НЕ вписывайте дубликаты в URL removal tool в Google Search Console. Этот метод временно перекрывает доступ ботов не совсем лишь к дублям, но и к необычным версиям.
6. НЕ канонизируйте HTTP, ежели на сайте есть версия странички с HTTPS-протоколом. Наличие SSL-сертификата (который поддерживает HTTP) является одним из причин ранжирования Google, потому переход на протокол HTTPS увеличивает позиции странички в поиске.
Кратко о главном
Итак, канонизация – это метод показать Google, какие странички преимущественно демонстрировать в поисковой выдаче.
Используйте эти четыре рекомендованных Google метода канонизации:
- Rel=canonical link tag – когда необходимо канонизировать HTML странички;
- Rel=canonical HTTP header – когда необходимо канонизировать не HTML-файлы;
- 301 redirect – когда контент навсегда переезжает на иную страничку;
- XML Sitemap - чтоб перечислить все канонические странички на сайте и облегчить боту сканирование (теги canonical также необходимо проставить) .
Чтоб улучшить краулинговый бюджет и выслать доходные странички в индекс, следуйте сиим советам:
- Не канонизируйте несколько URL-ов с схожим контентом различными методами;
- Нe используйте rel=canonical tag на страничках фильтров;
- Не используйте robots.txt для канонизации;
- Не линкуйте дубликаты снутри вашего сайта;
- Не отправляйте дубликаты страничек в removal tool от GSC;
- Не канонизируйте HTTP-страницы.
Комментариев 0