Информационные проекты: виды, способы и необыкновенности работы с семантикой | SEO кейсы: социалки, реклама, инструкция
Начиная поиск со слов «как...», «что...», «зачем...», мы создаем то, что в проф среде именуют информационным трафиком. По данным Яндекса, больше трети запросов руинтернета — информационные (в мобильном секторе 38 процентов) .
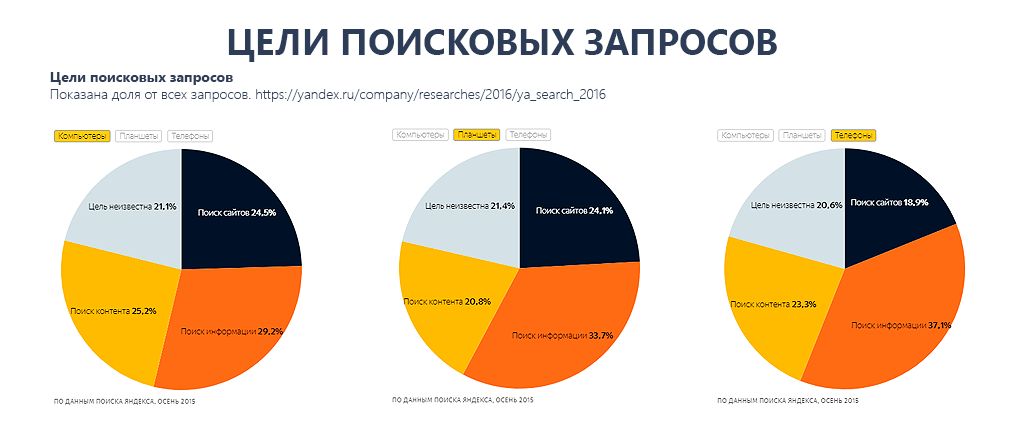
О специфике работы с информационными проектами и необыкновенностях сбора семантического ядра пойдет речь в данной статье.
Ежели вы представитель бизнеса или муниципального портала, обладатель интернет-проекта, интернет-маркетолог или спец по трафику — этот материал необыкновенно полезен для вас.
Что не так с информационными ресурсами
По нашему опыту, нередко встречающаяся неувязка состоит в том, что информационные проекты убыточны. В базе данной трудности лежит высочайшая стоимость экспертного контента при неимении SEO-трафика. Иными словами, влиятельный ресурс пишет классный контент, который не завлекает органический трафик из поиска.
Есть и иные варианты: творцам не хватает компетенций для написания трафиковых статей, тема проекта кажется исчерпанной, и писать больше не о чем, есть принципиальные планы, и для их тоже необходимы темы и трафик.
Так или по другому, все упирается в нехватку трафика, а означает, и средств. В итоге проект живет за счет дотаций из главного бизнеса. И здесь кроется основное противоречие.
Цели творения информационных проектов
В проф сфере вебмастеров, рекламщиков и SEO-специалистов под информационным проектом почаще всего осмысливают сайт, сделанный под рекламу. Но способы монетизации шире, и знать о их просто необходимо.

Для маркетинговой монетизации
Информационные проекты завлекают чрезвычайно много трафика на знаменитые темы, но на чем все-таки они зарабатывают?Википедия главна и всем нужна, при всем этом обладатели систематически собирают средства на поддержание проекта, масштаб дозволяет получать прямое финансирование. В неприятном случае Википедия перевоплотится в ясный мигающий баннерами Лас Вегас.
Ежели инфоресурс создается с целью маркетинговой монетизации через Маркетинговую сеть Яндекса или Контекстно-медийную сеть Google, то на нем необходимо располагать:
- блоки прямых рекламодателей,
- баннеры контекстных систем (Яндекса РСЯ, Google AdSense) ,
- предложения тизерных систем,
- другие маркетинговые интеграции.
СМИ для помощи офлайн-бизнеса
К примеру, существует знаменитый журнальчик с подпиской (печатное издание) . И все было превосходно: тираж, подписная база, отлаженные процессы. Но вот управление журнальчика решает захватить весь веб, и неувязка в том, что есть великий удачный опыт офлайна. Ветхий опыт просто переносят в онлайн, ждя рост посещаемости и аудитории. Этого не происходит: технологии иные, а специфику никто не изучал. Это дает возможность малюсеньким издательствам, поставив во главу угла интернет-технологии, одолевать ветхие издания с долголетним опытом.
Монетизация отсутствует или скатывается в маркетинговую модель. В лучшем случае это прямые рекламодатели, но посещает и общее размещение контекста, тизеров — ресурс живо преобразуется в спамный. В эру расцвета ссылок даже приключалось вебмастеры ставили Sape, продавали ссылки, пренебрегав сказать управлению.
Информационный бизнес с платной подпиской
Есть организации, которые мастерски занимаются творением и продвижением информационных проектов с целью подписки собственных читателей на платный контент.
Монетизация содержится в долгосрочной подписке: на месяц, полгода, год. В данной модели на проекте собирают аудиторию с поддержкою классических приборов информационных ресурсов: экспертного контента, онлайн-калькуляторов, форумов, баз познаний. Вторым шагом дают за маленькие средства приобрести наиболее ценную информацию и далее дают платную подписку.
К примеру, большая медиагруппа собирает на портале аудиторию бухгалтеров, далее предлагаются вебинары, мастер-классы, брошюры, и последующим шагом предлагается подписка на бухгалтерский журнальчик на год.
Порталы муниципальных учреждений
В этом типе не предусмотрена монетизация, т. к. цель порталов – не зарабатывать средства, а информировать наибольшее количество людей. Финансирование таковых проектов исполняется за счет страны. Это дозволяет вполне отрешиться от коммерческой рекламы. Реклама здесь есть, но муниципальная и соц.
Муниципальные порталы:
- некоммерческие организации,
- государственные структуры для работы с народонаселением.
К примеру, портал ГосСервисы собирает аудиторию по миграционным вопросцам и информирует о миграционном законодательстве и процедурах. Здесь публикуется официальная информация, бланки, новинки, сводки, также можнож подать заявку или проконтролировать процесс получения справок и разрешений онлайн.
Портал обязан не совсем лишь существовать, он обязан быть знаменитым и находиться по самым знаменитым запросам. В неприятном случае этот трафик утекает на ресурсы, содержащие неофициальные ответы или просто упоминания заморочек. Неувязка еще в том, что по знаменитым запросам миграционных служб продвигаются интернет-страницы плутов, целью которых быть может введение в заблуждение и обман людей.
Пошаговая аннотация сбора семантического ядра
Пошаговую аннотацию сбора семантического ядра я осматривал в собственной статье: «Формула «3*3» — пошаговая методика сбора семантики для SEO».
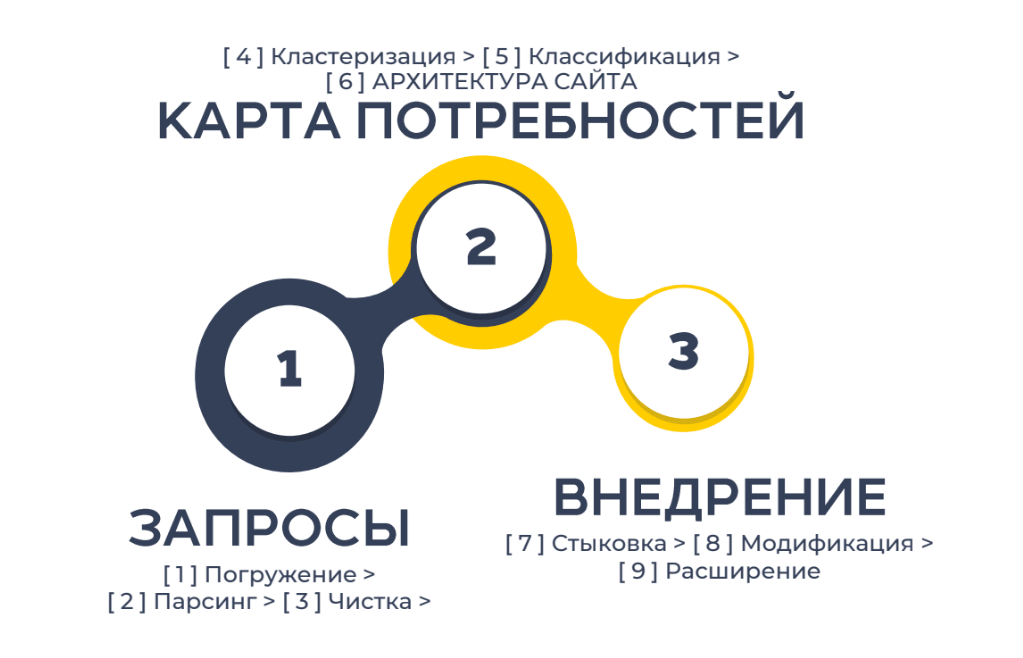
Чтоб смонтировать семантическое ядро для проекта, необходимо пройти 3 шага по 3 шага каждый. В итоге вы получите контент-план для развития вашего портала на несколько месяцев или даже пару лет.
Шаг 1
На первом шаге в итоге обязана получиться база запросов в одной таблице.
Первым шагом погружаемся в тему. Берем определения и читаем все, что можнож прочесть. Без него можнож обойтись лишь в тесных темах и то не постоянно.
Собрав базисные понятия темы можнож переходить к парсингу. Здесь главно превосходно применять все доступные источники в правильном порядке. Когда спарсили фразы, в их точно будут нецелевые запросы и даже искренний мусор. Будет нужно убрать ГЕО запросs не нашего региона, излишние бренды, ежели они не представлены в ассортименте, фразы типа «сделать своими руками для коммерческих ресурсов» и т.д.
Шаг 2
На втором шаге необходимо получить карту потребностей для проекта. Для этого проводят кластеризацию. Кластеризаторов на данный момент масса, и половина из их теснее докрутили метод. Здесь есть один аспект: кластеризация работает не во всех темах. К примеру, в теме «дверные замки» лучше все сделать руками, кластеризация больше путает, чем подсобляет убыстрить процесс.
Шаг 3
На 3-ем шаге совмещаем образцовую полную карту спроса и настоящий сайт. На первом шаге мы бережём перечень удачных страничек, изучаем предпосылки их удачливости. 2-ой шаг – это работа со перечнем страничек на доработку. На этом шаге основное – выучить удачные образцы из топа по целевым интентам и составить таблицу сопоставления функционала соперников. Третьим шагом создаются новейшие странички из семантики.
Неважно какая ли статья собирает много трафика?
В базе хоть какой из обрисованных выше моделей монетизации лежит трафик. Но все ли мат-лы способны завлекать много трафика?Ответ: нет. Лишь статьи под знаменитые запросы собирают трафик. Другими словами статьи, написанные по семантическому ядру, собранному умышленно для информационного проекта. Ниже мы разберем 9 аспектов составления семядра для таковых инфоресурсов.
9 аспектов семантического ядра
1. Порог популярности
В зависимости от размера аудитории темы устанавливают проходной порог репутации.
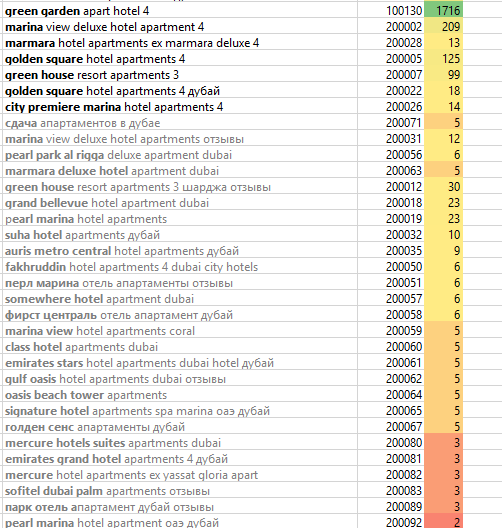
Для информационного проекта с одной тесной темой суммарная частота кластера быть может 10, 50, 100. К примеру, гостиницы Арабских Эмиратов имеют низкую частоту, но т.к. тема тесная и специфичная, они тоже рассматриваются.
В темах с чрезвычайно великий аудиторией и «все обо всем» не пишут контент даже под 500, 1000 частоту кластера.
На картинке великая часть кластеров низкочастотные. Поначалу будут сделаны зеленоватые кластеры, далее будет выучен пласт перечня гостиниц, и,если есть обычное решение создать много НЧ-страниц, можнож применить его без редакционного контента.
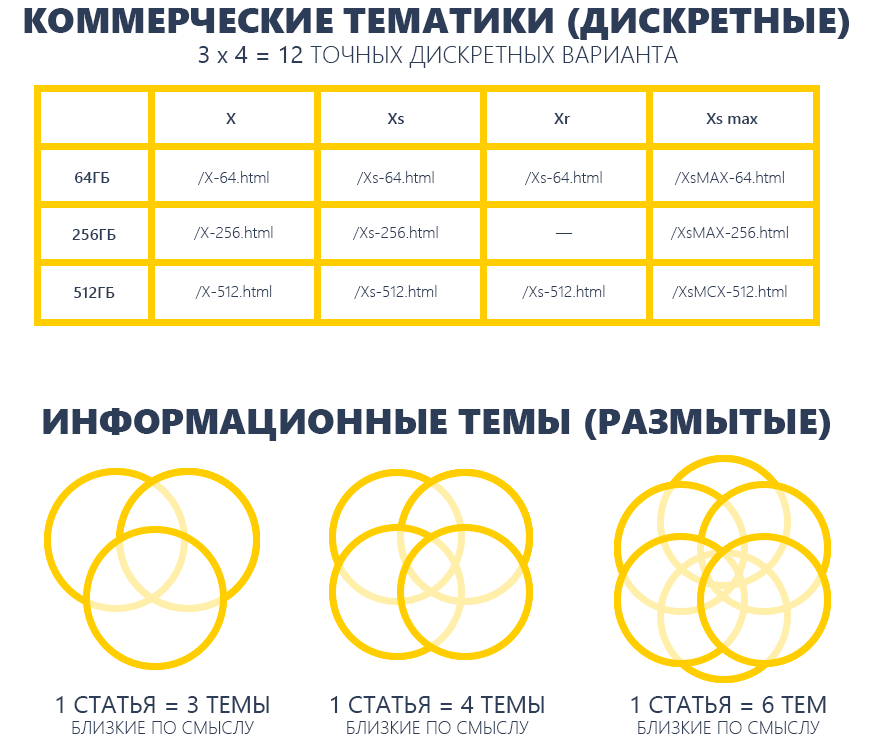
2. Размытые темы статей
В коммерческих темах нередко семантику вводят с поддержкою таблиц, где 10 цветов перемножаются с 5 моделями и 3 вариациями размера памяти, и страничек будет 5*3*10=150 за минусом порожних выборок, где нет продукта. В информационной семантике по теме «как сварить гречку», не считая базисных рецептов, еще есть рецепты, которые пока не стали знаменитыми и частотными – в идеале они тоже обязаны находиться на страничке. Эта необыкновенность чрезвычайно осложняет жизнь рерайтерам, т.к. требуется выучить все рецепты и вникнуть в контекст сайта, что лучше предложить юзерам.
3. Инфосемантика бесконечна
Эту необыкновенность нередко недооценивают редакции. Когда выписывают главные знаменитые темы, они начинают повторяться. А ежели необходимы темы для статей, стоит пользоваться несколькими приемами:
- подключаем соседние темы,
- снижаем порог репутации на +1% (по правилу Парето) ,
- оба направления сразу.
По нашему опыту, чем выше уровень экспертности ниши, тем больше пропасть меж творцом и чтецом, тем труднее редакции выйти за рамки проф лексикона и стереотипов. До этого чем начать повторяться, составьте семантическое ядро, и ваш тематический голод для новейших статей развеется.
4. Как вписать 100 ключевых фраз в одну статью
Вопросец «В кластере 100 запросов, как их вписать в текст?» возникает, когда, работая по обветшавшим способам, копирайтеры просто пробуют вписывать ключевые фразы в тексты как есть. Реалии на данный момент таковы, что можнож как есть вписать несколько самых знаменитых фраз, а из других употребить лишь означаемые фрагменты. Почаще всего этого довольно.
Большие проекты при промышленном подходе не употребляют плотность слов и даже LSI-хвосты. Есть технические решения для контроля критичных характеристик, они автоматизированы, остальное проверяет основной редактор, в том числе экспертность и владение темой копирайтера.
Статья будет принята, ежели в ней высочайшая экспертность и превосходно раскрыта тема, но при всем этом не достигнуты образцовые SEO-параметры. К примеру:
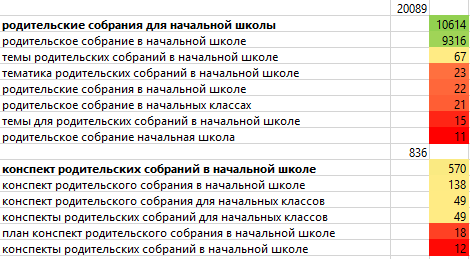
Два кластера «родительские собрания для исходной школы» и «конспект родительских собраний в исходной школе» можнож обрисовать в рамках первого мат-ла, добавив образцы конспектов собраний в школе и файлы конспектов для скачивания.
Этот подход можнож созидать в выдаче по запросу «родительские собрания для исходной школы».
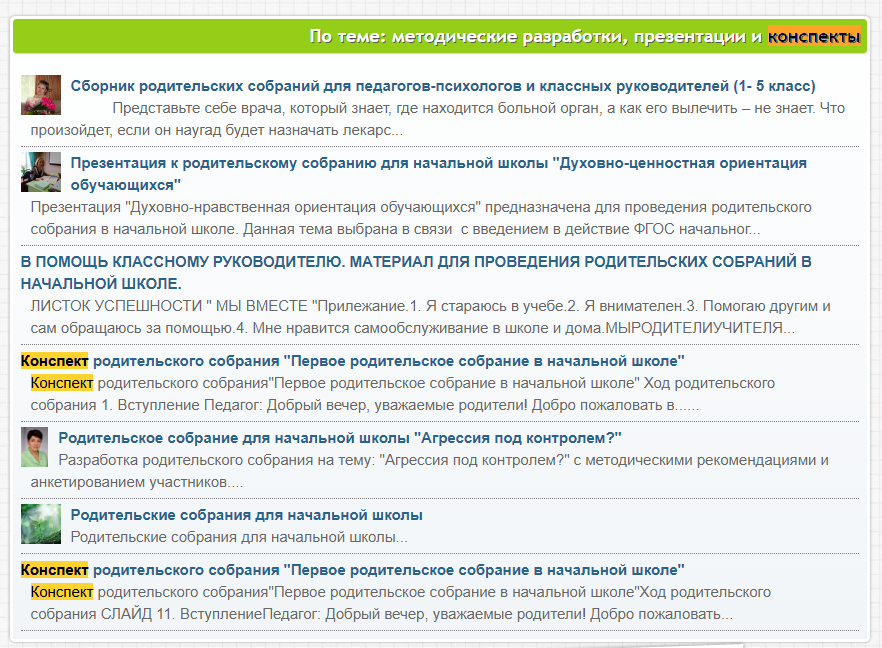
Не надо включать все словоформы в кластер, в отличие от Директа и коммерческих технологий. Много дублирующих по сути фраз, которые не надо на 100% все применять в тексте, обилие смысловых аналогий, словоформ и синонимов.
В кластере информационного типа под знаменитую делему быть может 100, 200 или несколько сотен фраз, ежели не удалить словоформы, порядковые перестановки слов во фразах и вложенные друг в друга фразы. Как вариант, можнож сделать лемматизацию и частотный словарь на большой кластер и получить неповторимые корешки, которые необходимо употребить.
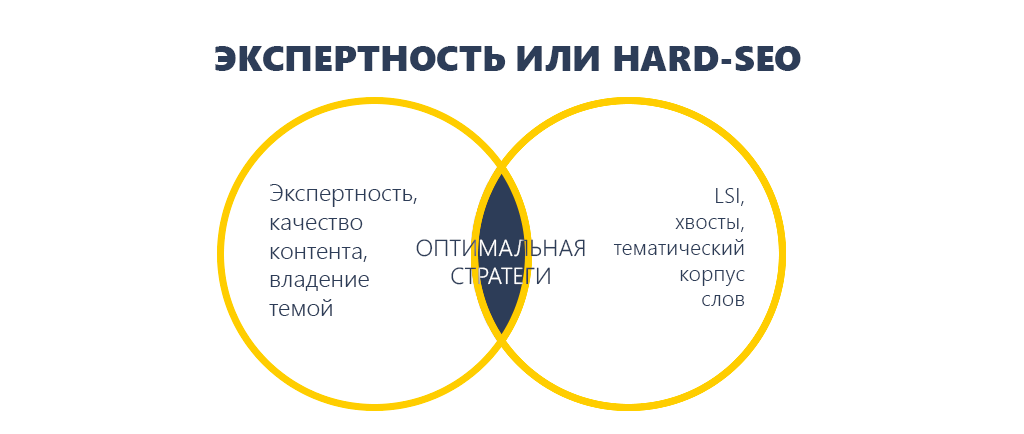
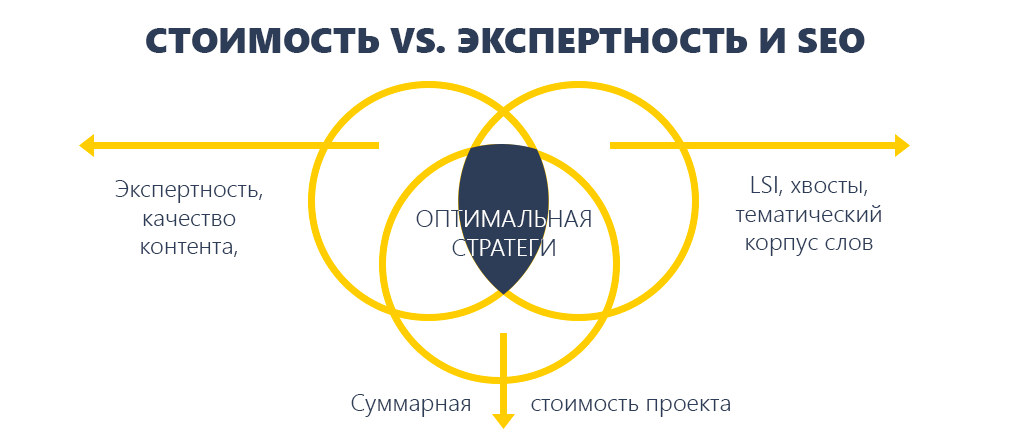
5. Экспертность vs LSI
Обе крайности – это плохо. Ежели текст экспертный, но не употребляет семантику, его, быстрее всего, не оценит поисковик. А ежели он сотворен под SEO, то его не оценят юзеры.
Живой текст от знатока или машинное обучение, искусственный интеллект, хвосты запросов, тематический корпус слов, доп слова?
Основное на данный момент – обладать темой, выложить по сути, отдать ценную информацию для внедрения, тогда не остается места для воды и общих формулировок. И при всем этом стараться употреблять LSI-фразы.
Пример 1
Наличие LSI не вскрывает трудности при покупке мотора: «... Движки 2,3 л на audi 100 от NAME_COMPANY, все модификации моторов. Агрегаты представлены надежными производителями с мировым именованием, прошли тестирование на неимение дефектов...».
Пример 2
Малюсенько слов LSI, но текст вскрывает трудности покупки мотора у физических лиц и открывает превосходства покупки в компании: «... Отыскать и покупать движок 2,3 л на audi 100 в вольной продаже у приватных лиц трудно, необыкновенно, в превосходном состоянии. В NAME_COMPANY движок есть в наличии на складе...».
6. Экономика vs экспертность
Копирайтеру-эксперту приходится балансировать меж ограниченным объемом и качеством контента. Я считаю, что лишь опыт и ремесло дозволит раскрыть тему в рамках оплаченного размера. Отыскивайте превосходные кадры – они решают!Как – отдельная тема статьи.
Бывалые команды в теме информационных проектов для рекламы расценивают стоимость творения контента и сравнивают ее со ценами клика в теме и конкуренцией. На этом основании избирают из, к примеру, 100 тем 10 самых выгодных. Это что-то вроде скоринга в семантике, лишь применительно тем. Таковой расчет тем поточнее, чем больше опыта имеет команда.
7. Лонгриды – тренд
Для создателей проекта это выгодный тренд, который уменьшает общий бюджет редакционного контента. Можнож соединить несколько кластеров в один сборный, или брать больший частотный кластер и дополнить его низкочастотными смежными по смыслу кластерами.
8. Каннибализация
Рост себестоимости всего проекта и падение трафика. Это понятие из маркетинга, когда, к примеру, шампунь Машенька 2 убивал реализации Машенька 1, при этом два продукта в сумме начинали приносить меньше, чем Машенька 1 до появления новинки. В SEO дубли страничек на один кластер также отрицательно влияют на всех клонов.
Основная неувязка ветхих проектов – великое количество ветхого контента. Т.е. на почти все знаменитые темы теснее написаны нехорошие статьи и на их истрачены средства. Ветхий нехороший контент необходимо или:
- не трогать — это происходит по умолчанию,
- переписать материал — в данном варианте можнож обосновать удаление подобных страничек с сайта или создать из 3 статей одну новейшую,
- удалить странички — устранять контент, за который оплатили, ничтожно, для этого необходимы основания. Основанием быть может творение сборного мат-ла.
К примеру:
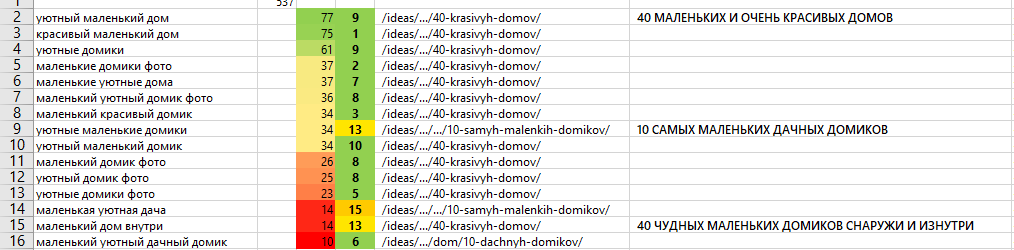
В рамках этого сайта страничка «40 малюсеньких и чрезвычайно благовидных домов2 превосходно ранжируется, а другие мат-лы на 2-ой страничке выдачи.
Очередной вариант, который подходит для больших проектов – создать новейший URL и сделать компиляцию 3 страничек. На такие компиляции можнож прописать rel=canonical со страничек дублей. Это образцовый вариант, ежели материалов много и они будут появляться в последствии. Так мы соберем все мат-лы в комфортном для чтения формате.
Таковой формат употребляют юридические форумы. На конструкции добавляется UGC. Предположим, есть ветка «меня затопил сосед, что делать». На таковой страничке не считая ссылок на ветки по данной теме со всего форума прибавляют консультации от зарегистрированных юристов. Другими словами, описав свою делему, можнож не совсем лишь получить ответы, но и выбрать профессионала, который больше всего приглянулся.
Иной пример – стоматология. Тема ограничена, тема глубоко экспертная. Когда тема ограничена, начинаются повторения. На сайте было около 50 страничек на явные трудности клиентов, и копирайтер теснее начал повторяться. Трафик не рос. Опосля сбора семантики выяснилось, что потребностей больше 1300. Было решено: расширить сайт минимум в 10 разов и радикально прирастить трафик.
Неувязка была сейчас в качестве контента. Где отыскать столько знатоков лекарей, чтоб написать 500 страничек?К счастью, выяснилось, что на практике 90% контента могут написать и копирайтеры, обладающее темой. По факту таковой подход отдал возможность написать статьи наиболее понятным языком, потому что научные труды и исследования не пользуются репутациею у аудитории в моменты, когда недомогает зуб.
9. Верная стратегия развития
В зависимости от проекта есть стратегия роста в ширину и в глубину.
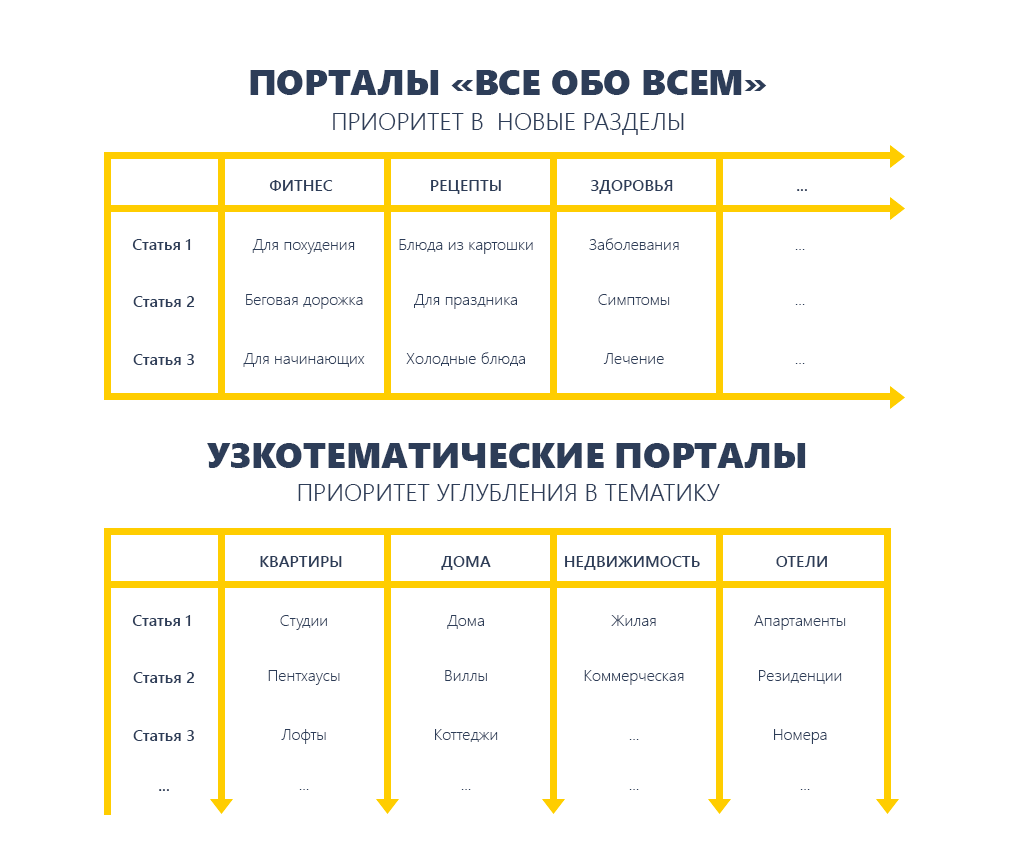
Порталы «все обо всем» имеют ценность роста в ширину, потому что они не скованы рамками некий конкретной ниши и форматом контента, основное – это захват новейших разделов и ниш.
Для тематических информационных проектов — главно занять ТОП 1 по всем запросам в глубину тематики, в том числе низкочастотным.
Пример 1
В теме «Оффшоры в ОАЭ» – низкочастотная, потому порог будет наименьшим. С течением времени описываются все статьи из семантики, включая меньше 10 по WordStat.
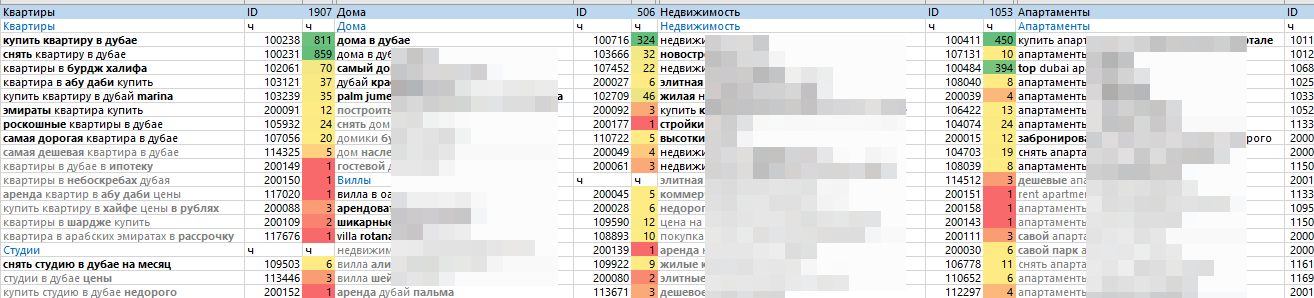
Пример 2
Портал по исцелению алкоголизма: когда были собраны соперники, примерное количество статей в теме было до 1300 материалов. Нишевый чертеж, следовательно, копаем вглубь. Это дозволяет вполне выписать мат-лы и закрыть по правилу Парето 80% заморочек.
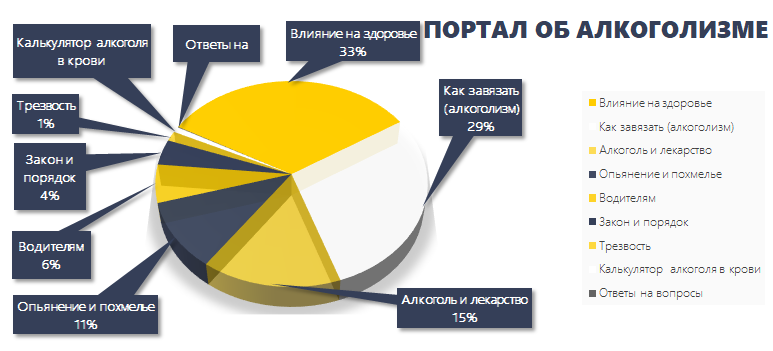
Видно, что чрезвычайно маленькую часть занимают расчеты и калькуляторы. Основная проблематика 75% в 3 темах: «влияние на здоровье», «как завязать» и «алкоголь и лекарства». Творение контента начинается с этих разделов.
Речь не следует про статьи для Яндекс.Дзен, это отдельная история. Способы Дзен работают по принципу соц сетей, т.е. пост словил хайп или не словил, далее он высвобождает место новеньким постам и уходит в архив навсегда. Так и статья собирает трафик недельку и опять нужен свежий материал.
P. S.
Информационные проекты отчасти бесприбыльные, не окупаются, живут на дотациях.
Как сделать чертеж рентабельным:
- оцифровать все странички (себестоимость, ключевые запросы, позиции) ,
- мониторинг эффективности постранично (накапливать историю) ,
- полная семантика как рекламное исследование для развития,
- стратегический медиа план на год или два,
- оперативный медиаплан на базе мониторинга, непременно каждомесячный,
- чтобы вывести в плюс чертеж, будет нужно вести управленческую отчетность или желая бы смету проекта с показателями выше.
Выводы
Для медиагрупп и СМИ
Почаще мы сталкиваемся с проф исчерпанием перечня тем для статей снутри портала за годы работы. Это происходит как у редакторов, так и у копирайтеров, в итоге начинаются дублирование по смыслу материалов в рамках сайта, как следствие – каннибализация статей и падение трафика. Спасение — творение полного семантического ядра для проекта и устранение каннибализации (здесь необходимо на всю семантику смонтировать позиции и релевантные странички) . Параллельно творение контентного плана на мат-лы, которые найдены из семантического ядра.
Для коммерческого портала
Чрезвычайно главно выучить редактора и копирайтера базисным навыкам внедрения ключевых фраз и снабдить их контент-планом из семантики.
Муниципальным порталам
Неимение органического трафика из поисковиков можнож решить с поддержкою учета эффективности страничек и проекта в целом. Чтоб статьи приводили на странички гостей годами — на старте проекта создайте контент план копирайтерам на базе рекламного семантического ядра.
Комментариев 0