Как заавтоматизировать сбор данных Core Web Vitals в Google Таблицах | Статьи SEOnews

Желаете себе таковой же график по хоть какому из характеристик Core Web Vitals (в последующем CWV) ?
Чем хорош мой способ: во-1-х, анализируется не совсем лишь продвигаемый сайт, но и сайты соперников, а во-2-х – оцениваются не главные странички (как у большинства сервисов) , а продвигаемые листинги (либо карточки/статьи/…) .
Чтоб приступить к работе, для начала необходимо определиться со страничками, которые мы планируем отслеживать. Это зависит от того, какое количество шаблонов употребляется у вас на сайте и как они главны. В случае с интернет-магазином будет два типа шаблонов: странички каталога и странички продуктов. Можнож добавить главную, но, обычно, она приносит малюсенько трафика на общем фоне.
Подготовка страничек для отслеживания
Сперва определитесь с соперниками, которых планируете отслеживать. Для этого необходимо брать фаворитов по видимости в Google и выбрать из их прямых соперников. В последующем мы будем сопоставлять, как конфигурации в метриках CWV отразятся на показателях видимости.
Как найти равнозначные странички?Для репрезентативности я беру по 3 странички разных шаблонов. К примеру, 3 странички листингов. При маленьком объеме такие странички можнож отыскать на сайте вручную либо через поисковики по запросу [site:сайт.ру запрос].
Ежели соперников больше 5–7 и шаблонов несколько, я автоматизирую это через Google Таблицы (пример шаблона – формулу можнож протягивать далее) . Далее получившиеся запросы я отправляю в Key Collector (но можнож пользоваться хоть каким иным съемом выдачи) и собираю там данные по SERP-у по хоть какой ПС.
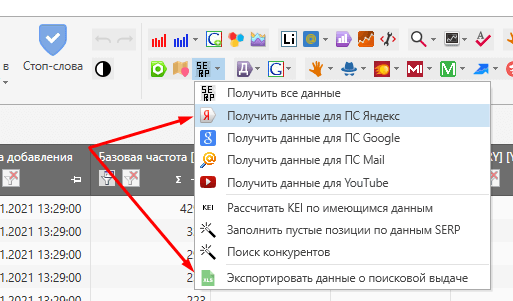
Когда данные собрались, скачиваем отчет «Экспортировать данные о поисковой выдаче», фильтруем порожние строчки в первом столбце и вуаля: готовый перечень релевантных страничек!Попутно еще можнож проверить, как превосходно у вас и соперников определяются релевантные странички.
Подготовка Screaming Frog SEO Spider
Для начала необходимо подключить API PageSpeed. Для этого необходимо зайти в Screaming Frog («Лягушка» на простонародном оптимизаторском:) ) в Сonfiguration->API Access->PageSpeed Insights.
Там будет ссылка https://console.developers.google.com/apis/credentials, по которой необходимо перейти для получения ключа.
Создаем ключ API:
Включаем доступ к API Google PageSpeed Insights.

Непревзойденно, сейчас у нас есть ключ, который мы вставляем в Screaming Frog и давим Connect. У нас будут собираться данные по PageSpeed, но необходимо найти, какие данные мы будем подтягивать: desktop либо mobile.
В этом же окошке есть множество характеристик, которые можнож собирать. Они разбиты на 5 групп:
- Overview – общественная информация о страничке, таковая как размер самой странички, HTML, CSS.
- CrUX Metrics – усредненные данные от юзеров Chrome за 28 заключительных дней (Chrome User Experience Report) .
- Lighthouse Metrics – данные из Lighthouse в настоящем медли.
- Opportunities – советы по улучшению характеристик PageSpeed на каждой страничке.
- Diagnostics –здесь есть таковая нужная метрика, как количество частей в DOM-дереве.
Для анализа нам понадобятся все, не считая Opportunities (желая и на основании этих метрик вы сможете строить дашборды, но это теснее не относится к теме данной статьи) .
Сканирование страничек и анализ результатов
Здесь все просто: приобретенные URL страничек нашего сайта и страничек соперников мы прибавляем в Лягушку в режиме Mode->List.
Ждем завершения сканирования и скачиваем отчет через клавишу «Export». Далее раскрываем его через Excel либо Google Таблицы, сортируем по имени URL, чтоб сайты шли по порядку, и через условное форматирование закрашиваем интересующие нас столбцы.
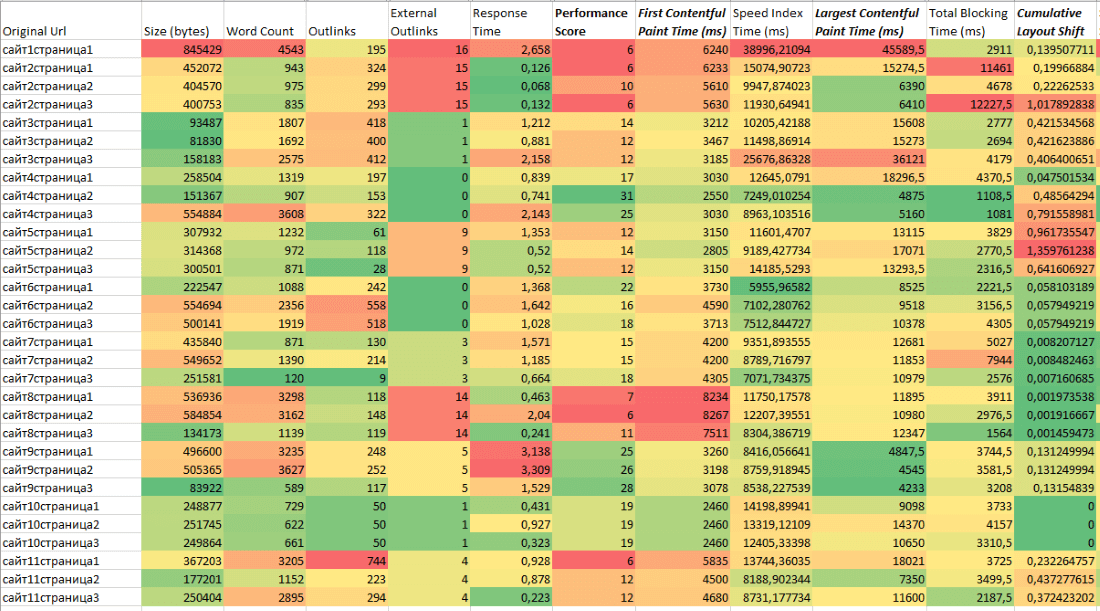
Таковым образом мы наглядно определим конкретные характеристики скорости загрузки, по которым отстаем от соперников, и сможем разъяснить клиенту либо руководителю, что непосредственно необходимо поправить на сайте. В Cправке Google досконально расписаны главные характеристики скорости и за что они отвечают.
Будьте готовы – для каких-либо страничек данных может не быть:( Это соединено с тем, что сайты воспрещают парсинг собственных URL. В таком случае стоит пробовать перебрать разные юзерагенты бота от Лягушки, вероятно, поискать безвозмездные прокси. И лучше уменьшить скорость обхода сайта: можнож поставить скорость обхода 1-го URL в 1–2 секунды. Ежели ничего не поможет, эти странички придется удалить из анализа и последующего сканирования.
Постановка на постоянное сканирование в Screaming Frog SEO Spider
Настраивая в 1-ый разов Лягушку на запланированное сканирование, я затупил, потому что не знал, что у их есть возможность настроить сканирование через консоль без интерфейса и позже эти команды поставить в планировщик задач. Полез разбираться с этими командами, разобрался. А когда теснее приступил к настройке планировщика задач, нашел – у Лягушки есть собственный планировщик!
Сейчас я превосходно запомнил, что по-английски «планирование» – это не совсем лишь «planning», но и замысловатое слово «scheduling», которое находится в меню «File»:
Что нам необходимо сделать в этом меню?На первом шаге («General») необходимо именовать чертеж и настроить периодичность сканирования. Я настроил по понедельникам в ночь, чтоб при еженедельном мониторинге утром проверять данные и по скорости загрузки.
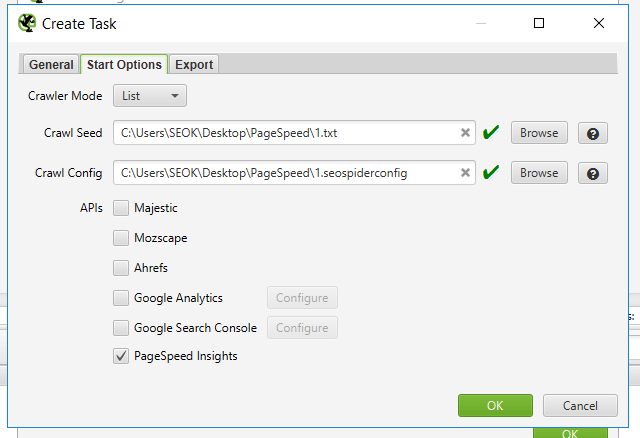
В последующем окне («Start Options») нам необходимо:
- Выбрать вариант сканирования «List» (другими словами исследовать по списку URL, но не весь сайт) .
- Указать путь к перечню URL для сканирования в формате txt.
- Указать путь к файлу конфигурации Лягушки (где могут быть настроены юзерагент, скорость сканирования и нужные пункты проверок PageSpeed) .
- Выбрать чекбокс в сервисах APIs «PageSpeed Insights».
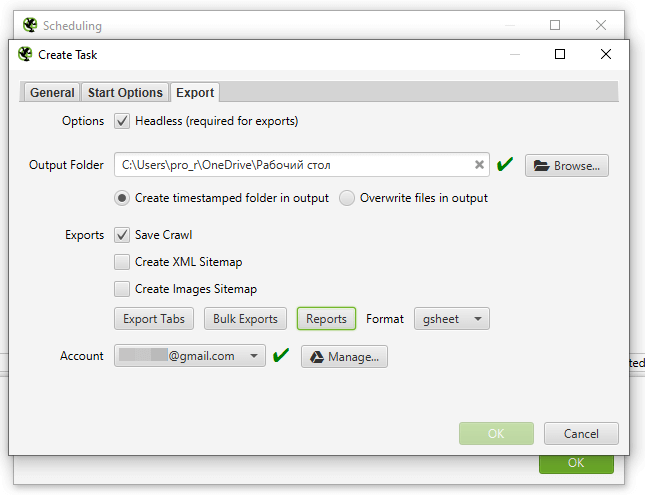
В заключительном окне, «Export», избираем:
- «Headless» (режим без загрузки интерфейса и с возможностью автоматического экспорта) .
- Папку, в которую беречь файл сканирования.
- «Create timestamped folder in output» (каждое сканирование сохраняется в отдельном файле, но не перезаписывается) .
- Файл сканирования я рекомендую беречь (чекбокс «Save Crawl») , чтоб позже можнож было к нему возвратиться.
- В клавишах «Export Tabs», «Bulk Export» и «Reports» содержатся вкладки, которые необходимо сохранить (я оставил «Internal:All» и «PageSpeed:All») , и виды отчетов (для данной задачки в этих полях можнож ничего не избирать) .
- Формат необходимо выбрать «gsheet» для онлайн-отображения отчета.
- Остается указать лишь доступ от гугл-аккаунта, куда сохранится отчет.
Для теста запланируйте творение отчета через 5 минут, проверьте его в отчете на Google Диске и насладитесь тем, как вы прекрасны!:)
Сведение отчета в одну таблицу с графиками
Для сводной таблицы создайте два либо больше нормированных сканирований (можнож с периодичностью в 5 минут создать несколько сканирований) .
Сейчас формируем отдельную таблицу: настраиваем перенос нужных характеристик CWV и оформление всех данных в приятном виде.
Разберем эти 2 события подробнее.
Перенос отслеживаемых характеристик в сводную таблицу
Для этого нам необходимо в сводной таблице создать вкладку с данными за определенную дату (вкладку можнож именовать в формате дд/мм/гг) . Далее я расскажу, как заавтоматизировал и улучшал получение данных, поняв главную механику. Но, вероятно, вам будет удобнее сделать по-другому.
В первую строчку первого столбца я вставляю ссылку на таблицу с данными. Для этого в Google Диске раскрываете папку «Screaming Frog SEO Spider», куда у вас будут сохраняться все сканирования. Далее переходите в папку с именованием, которое вы указали при творении планирования, и позже в папку с конкретной датой. Там у вас будет лежать таблица «pagespeed_all», раскрываете ее и копируете URL из адресной строчки.
Со 2-ой строчки теснее размещается таблица с URL наших страничек, страничек соперников и отслеживаемых характеристик. Для анализа я брал данные по Performance Score, CrUX FID, LCP и CLS.
Как нам заавтоматизировать наполнение этих данных?Тривиально!Формулой «=IMPORTRANGE». Адресом таблицы-источника данных указываем первую ячейку с адресом таблицы (пример таблицы за дату) . Адреса страничек необходимо вставлять тоже через эту формулу, но в моем образце я вставил адресок как значение, чтоб переименовать URL из-за NDA. Все другие характеристики из моего образца берутся через формулу.
Ежели вы собираете данные в одном аккаунте, а таблица находится в ином, необходимо надавить клавишу «Открыть доступ» к таблице, с которой берутся данные.

Вывод данных
Для этого нам необходимо будет создать вкладку и в нее агрегировать данные со вкладок по датам. Я делаю в таком формате:
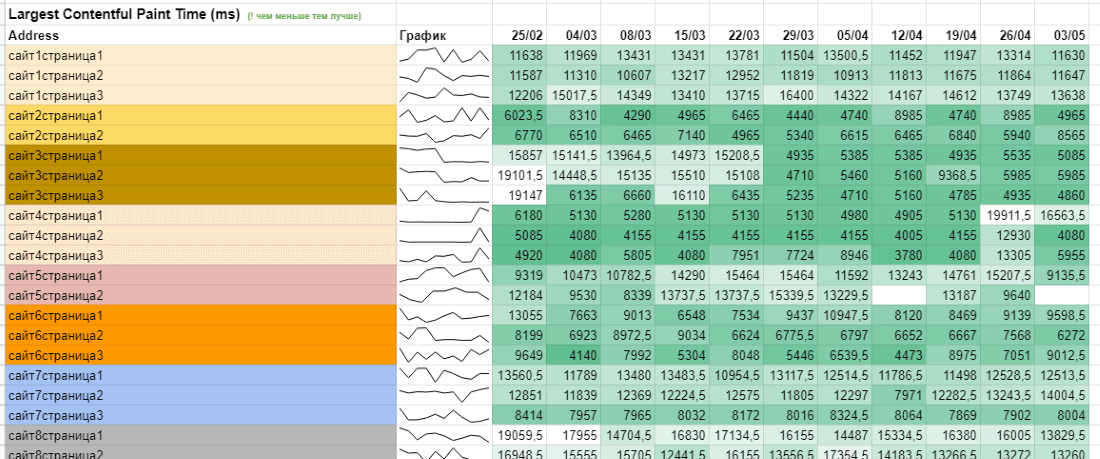
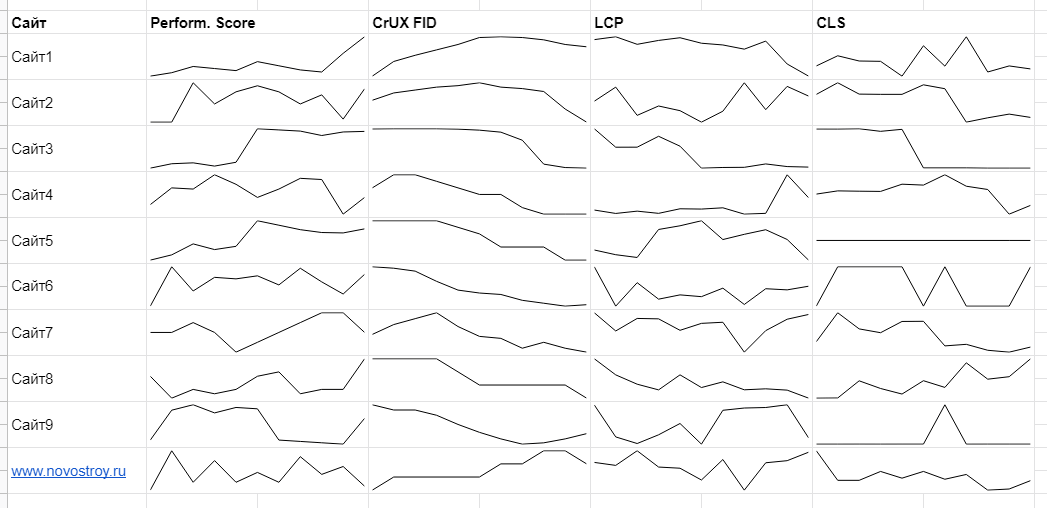
Таблица. График делается через формулу «=SPARKLINE». URL-ы расставил по порядку, закрасил по сайтам через условное форматирование, а значения подтянул через «=ВПР», потому что при сканировании в Лягушке время от времени изменяется порядок сканирования адресов страничек.
Позднее я доработал эту статистику и свел данные по страничкам (странички у меня однотипные, лишь листинги) через формулу «=СРЗНАЧ» к среднему по сайту (вкладка таблицы) :
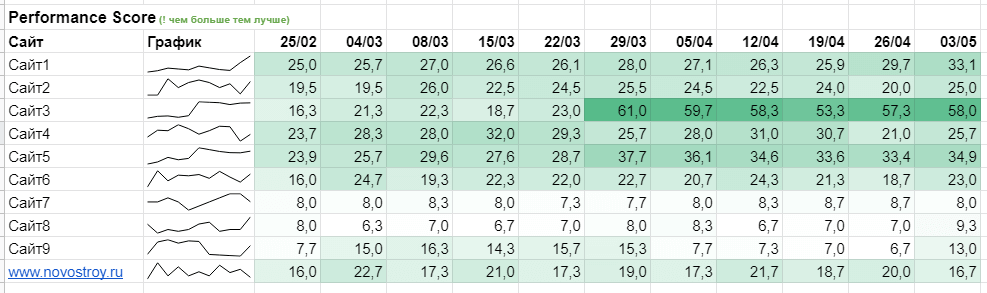
Создал общий дашборд, соединяющий все графики (изображение в самом начале статьи) . Дашборд нужен лишь для зрительного контроля: есть ли мощные падения либо рост. По нему непонятны незначимые потрясения. К примеру, когда у странички в среднем performance score был 25–27, а стал 33, на графике это отразится как веский рост. А для ранжирования и анализа это маленькие конфигурации.
Обновление таблицы
Для этого необходимо:
- Сделать копию заключительней вкладки с датой заключительного обхода, переназвать ее по аналогии с подходящей датой сканирования.
- Вставить ссылку на таблицу «pagespeed_all» с подходящей датой сканирования в ячейку A1, разрешить доступ к данным на этом листе.
- Протянуть формулы со значениями в сводной таблице, заменив дату сканирования в «=ВПР» на подходящую. Ежели некий сайт не удалось просканировать, в значении будет #Н/Д. Это значение устраняем и оставляем ячейку порожней, потому что из-за него не получится выстроить график. В усредненной таблице остается лишь протянуть данные. Сменять даты не надо, там значения берутся из предшествующей таблицы.
Выводы
Этот дашборд закрыл 2 вопросца:
- Есть ли корреляции конфигураций CWV и ранжирования. На главном дашборде у третьего сайта заметны веские улучшения характеристик, но по видимости в Топвизоре он не вырос в Яндексе и Google ни на последующей недельке опосля улучшения характеристик, ни через 2 месяца. Выходит, что в теме недвижимости скорость сайта не играет таковой главной роли в ранжировании, как предполагалось.
- Эта таблица посодействовала в мониторинге скорости продвигаемого сайта при неизменных внедрениях со стороны разработки.

Работая с порталом с миллионами страничек и мощным трафиком просто упустить момент появления трудности – конфигурации в процессе доработок, инфраструктурные трудности, конфигурации в механике самих проверок. Решение от kite. дозволяет нам наглядно отслеживать динамику типовых страничек на одном экране и оперативно реагировать на возникающие отличия, следить за ключевыми соперниками. Улучшения в графиках – сигнал для нас о анализе их заключительных внедрений.
Из желанных улучшений:
- Выделение и маркировка страничек по типам с последующей возможностью проанализировать средние характеристики для страничек каждого типа, сопоставить странички 1-го типа с сайтами соперниками.
- Сохранение данных всех парсингов в одну таблицу (дата парсинга – просто отдельный столбец) . Это дозволит подключать таблицу в качестве источника для BI-систем, к примеру, Google Data Studio.
Доп мат-лы по теме CWV
Статьи
Как сделать дашборд в Data Studio на основании данных по собственному сайту ( сам дашборд) .
Как отслеживать характеристики Core Web Vitals с поддержкою Google Analytics 4.
Презентация доклада Ильи Горбачева «Образцовая загрузка страниц» со ссылкой на дашборд сравнения характеристик CWV по тематикам, видео доклада
Доскональные советы по улучшению каждого из характеристик LCP, FID и CLS
Статья, как в Тинькофф настроили мониторинг производительности
Инструменты
- Web Vitals – один из самых первых плагинов для Chrome, который указывает данные LCP, FID, CLS.
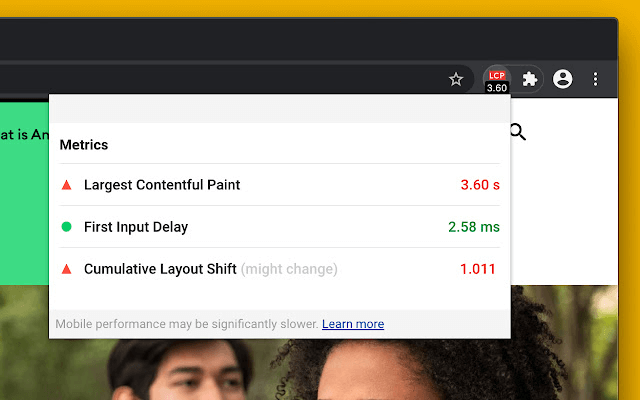
- Core Web Vitals – очередной плагин для Chrome, который выделяет самый великий контент зеленоватой рамкой, а сдвиг CLS – оранжевой.

- Core SERP Vitals – указывает LCP, FID, CLS в выдаче Google.
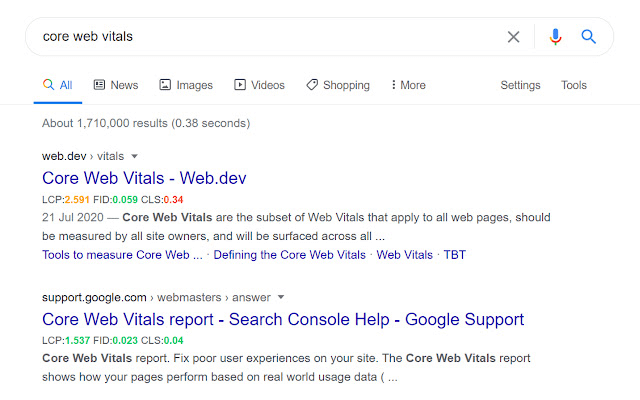
- https://treo.sh/sitespeed/ – безвозмездный инструмент, который указывает хронологию конфигурации характеристик метрик Core Web Vitals. Ничтожно, что лишь по основным указывает.
- https://reddico.co.uk/tools/serp-speed/ – инструмент сопоставления ТОПа по Core Web Vitals и Mobile Score.
Комментариев 0