Язык постоянных выражений для маркетолога: управление для начинающих | SEO кейсы: социалки, реклама, инструкция
В работе интернет-маркетолога нередко приходится сталкиваться с постоянными выражениями: кластеризация семантики, анализ соперников, работа с данными веб-аналитики, настройка редиректов и сервисов интернет-маркетинга.
Большая часть руководств по RegExp трудны и нацелены на технарей, при всем этом абстрактно обрисовывают область внедрения этого прибора.
В статье желаю поделиться частыми кейсами внедрения постоянных выражений в интернет-маркетинге, отдать советы по инструментарию, который дозволит каждодневно применять постоянные выражения в работе.

Постоянные выражения Старой Греции
Intro
Материал рассчитан на интернет-маркетологов и SEO-специалистов без опыта в программировании, содержит упрощения и терминологические неточности. Это осознанный шаг для понижения порога входа в тему.
Постоянные выражения – это последовательности знаков (масок) , которые определяют поисковые паттерны при использовании операции «найти/заменить». Синтаксис RegExp поддерживается обилием прибавлений и сервисов.
Но не будем начинать с описания синтаксиса, а лучше давайте сходу поглядим, как и где постоянные выражения используются, какую выгоду можнож извлечь, а когда будет понятна ценность – вы можете расширить и закрепить приобретенные познания.
1. Настройка целей в Google Analytics
Допустим, на нашем сайте есть коллтрекинг и форма обратной связи, а при отправке формы либо звонке по подменному номеру коллтрекинга в Google Analytics отправляются действия, которые числятся в различных целях.


Для оптимизации кампаний по CPL будет удобнее параллельно считать эти действия в общей цели. Постоянные выражения дозволяют решить эту задачку и поддерживаются Google Analytics. Поглядим, как будет смотреться настройка общей цели:
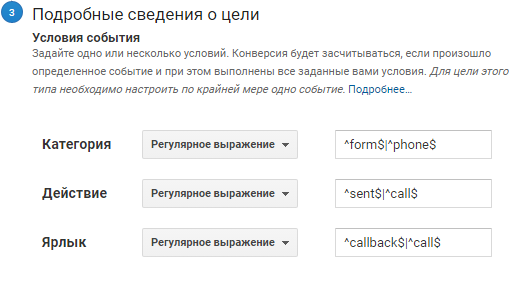
Опции для общей цели в Google Analytics
Разберем значения полей, чтоб понять условия срабатывания:
- «|» – вертикальный разделитель, логическое «ИЛИ». Поначалу проверяется условие слева от разделителя, позже условие справа. В нашем случае это вхождение form либо phone в категорию, sent либо call в событие и так дальше.
- «^» – крышечка, начало строчки и «$» – бакс, конец строчки. Используем, чтоб исключить неправильное срабатывание, ежели некий сервис будет отправлять не одноименное, но похожее имя действия (категории, действия, ярлычка) .
Источников событий быть может много – email-трекинг, онлайн-чат, виджет обратного звонка. С поддержкою регулярок просто объединить все эти действия в одной цели.
2. Настройка показа через Google Tag Manager
Частая задачка при подключении виджетов через GTM – выбор страничек показа. К примеру, мы решили применять виджет с Pop-up формой «Подпишитесь на рассылку» для сбора email-адресов в разделе «Статьи».
Google Tag Manager также поддерживает синтаксис постоянных выражений, настроим триггер для виджета, который желаем демонстрировать на страничках статей:

У нас возникли новейшие знаки: «.» – точка, хоть какой знак (буква, цифра, спецсимвол) , в сочетании со звездочкой «*», означает хоть какое количество всех знаков, другими словами всякую страничку, вложенную в articles, включая ее саму.
3. Настройка редиректов в.htaccess
С настройкой 301 редиректов почаще сталкиваются создатели и SEO-специалисты, но и для интернет-маркетолога навык не будет излишним. Собственно меня познание этого функционала нередко выручало в «переездах» меж сайтами и фиксинге заморочек.
Допустим у нас был сайт, где все сервисы лежали по адресу http://example.org/uslugi/*, а все статьи по адресу http://example.org/stati/* – на новеньком сайте все мат-лы переехали в иные разделы, при всем этом адреса всех вложенных страничек сохранились.
Ежели страничек немножко, можнож пойти обычным методом и прописать редиректы для каждой, но что ежели страничек сотки либо даже тыщи?Здесь не обойтись без постоянных выражений. Итак, подключаемся по FTP/SSH, раскрываем.htaccess и вносим правки:
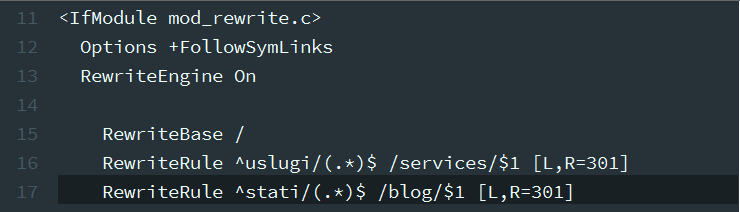
Не будем вникать в синтаксис.htaccess, а сосредоточимся на используемых постоянных выражениях. Здесь мы видим знакомые нам знаки начала строчки «^» и конца строчки «$», также хоть какого количества всех знаков «.*».
Знаки «.*» заключены в скобки, а в конце верховодила перенаправления возник «$1». Скобки можнож именовать запоминающими – они берегут заключенную в их последовательность для каждой строчки и передают ее в переменную $1.
Таковым образом хоть какое перенаправления с хоть какой странички будет корректно переадресовано в новейшую директорию не будет нужно прописывать кучу редиректов.
4. Экспорт в электронную таблицу
Иная частая задачка – когда надобно смонтировать информацию из какого-то сервиса и представить ее в табличном виде, а экспорта данных в CSV нет.
К примеру, мы решили выбрать заглавие для собственного лампового блога по интернет-маркетингу и нагенерили 1000 разновидностей доменных имен.

Перечень доменов опосля генерации
Позже мы их пакетно проверили на возможность регистрации и сейчас желаем сделать табличку и выбрать идеальный вариант с учетом стоимости и способности регистрации.
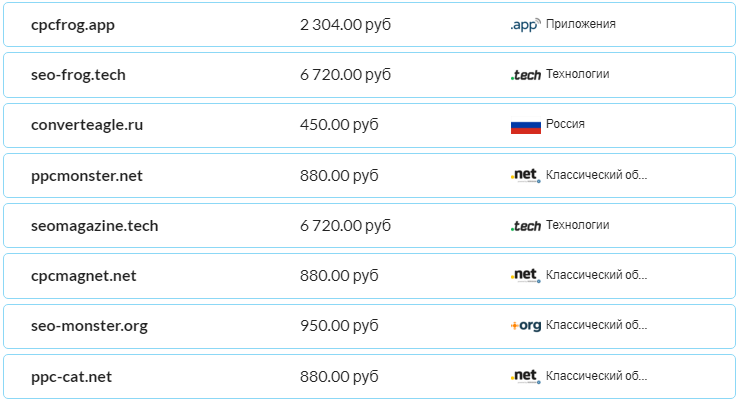
Результаты пакетной проверки доменов
Ежели мы попробуем скопировать эту информацию в электронную таблицу, то получим много строк никак не разделенного текста. А мы желаем, чтоб домен, стоимость, доменная зона и ее тема были в различных столбцах для фильтрации данных.
Под решение данной задачки будет нужно среда для работы с постоянными выражениями. Самое комфортное решение – это приложение Notepad++, вероятен также и вариант внедрения надстройки для Excel либо иных программ, к примеру, Calc Open Office (аналог MS Excel) поддерживает регулярки «из коробки».
Скопировав результаты проверки в файл получим: домены с новейшей строчки, цены – тоже с новейшей строчки, все данные разделены пробелами, без табуляции.

Напомню, мы желаем получить таблицу, где 1-ый столбец с доменным именованием, 2-ой с ценой, 3-ий с доменной зоной, 4-ый – тема доменной зоны.
Для этого нам надобно будет выполнить несколько поочередных событий. В нашем образце мы работаем с тыщами доменов и сделать это руками – не вариант.
Последовательность операций «найти/заменить», которые приведут нас к результату:
1. Убрать пробел, отделяющий разряды в стоимости.
Условие поиска: ([0-9]) ( [0-9][0-9][0-9]) – обретаем числа, разделенные пробелами, и запоминаем их в 1-ые и 2-ые запоминающие скобки.
Условие подмены: $1$2 – итог первых запоминающих скобок ($1) прибавляем ко второму ($2) , без пробела.
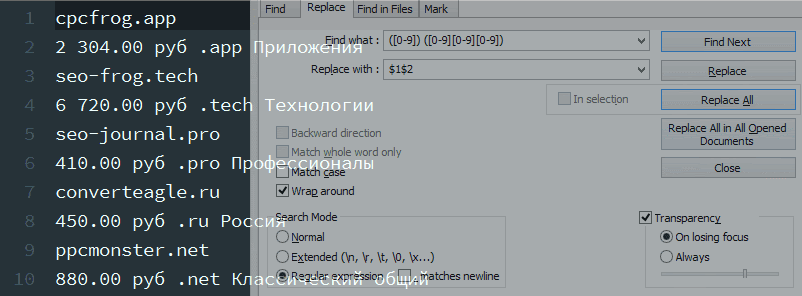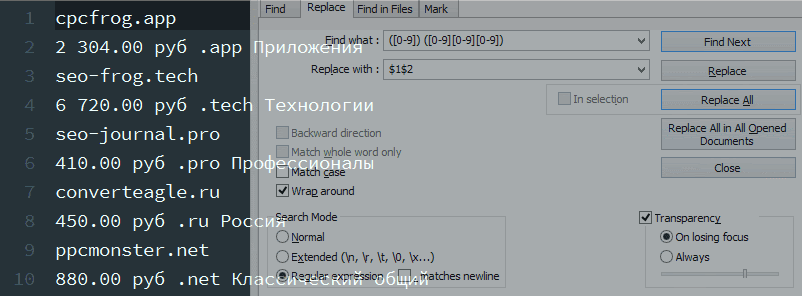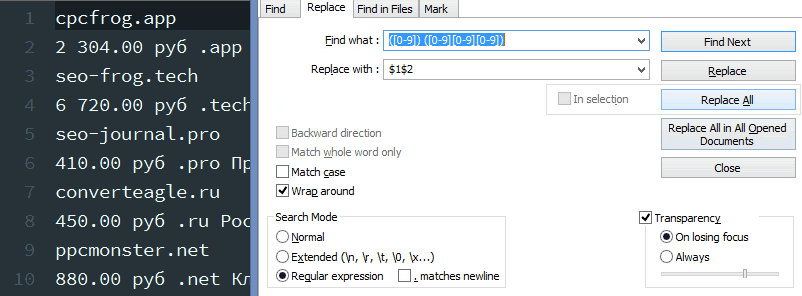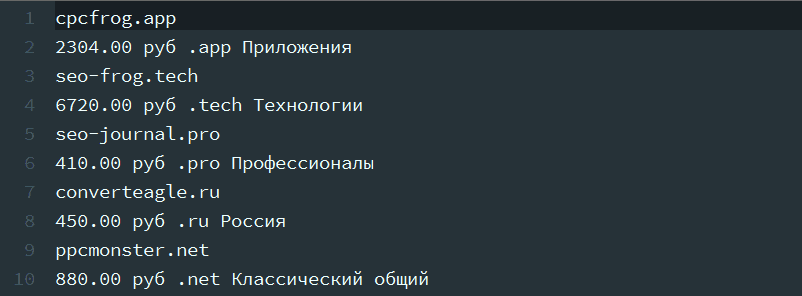
Удаление пробела
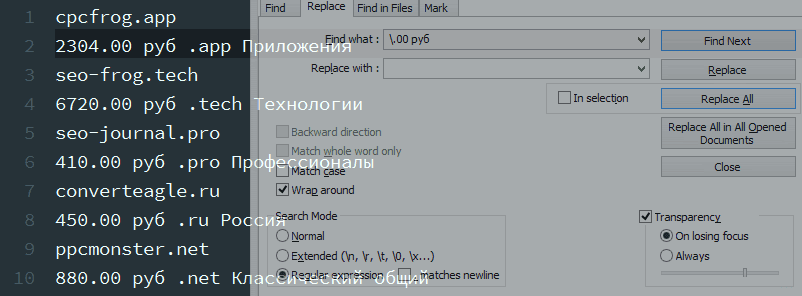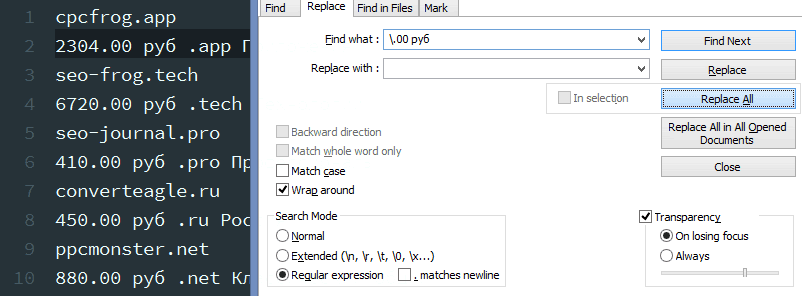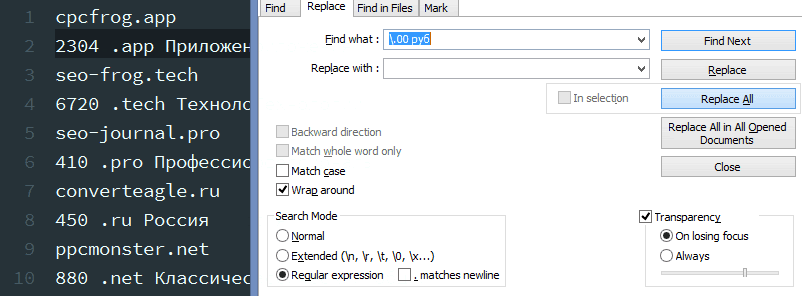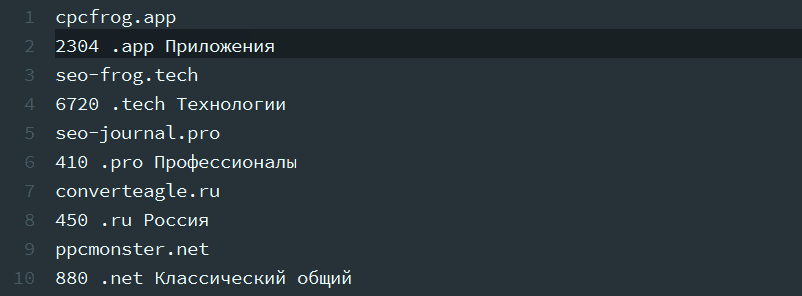
2. Убрать копейки и «руб» из цены.
Условие поиска:.00 руб – чтоб «.» была не хоть каким эмблемой, а точкой, перед ней надобно добавить обратный слеш (экранировать)
Условие подмены: порожняя строчка.
Удаление копеек
3. Убрать переносы строк.
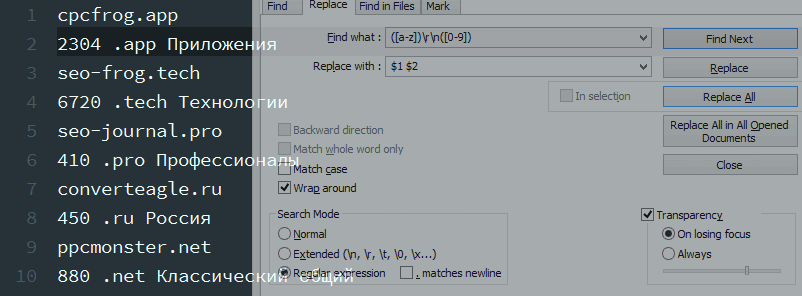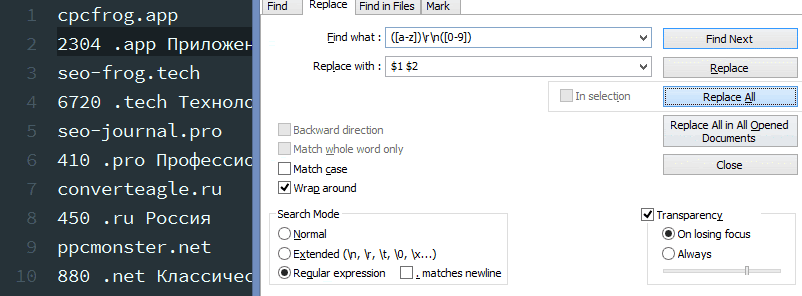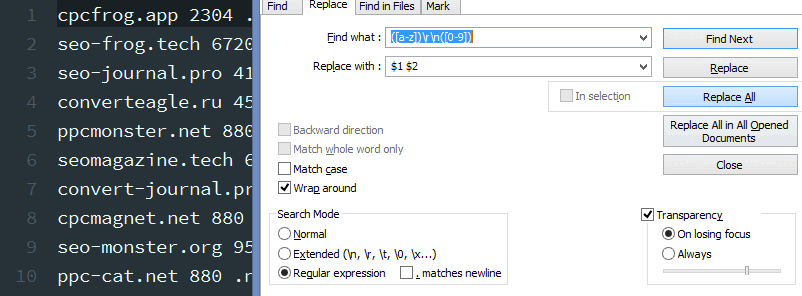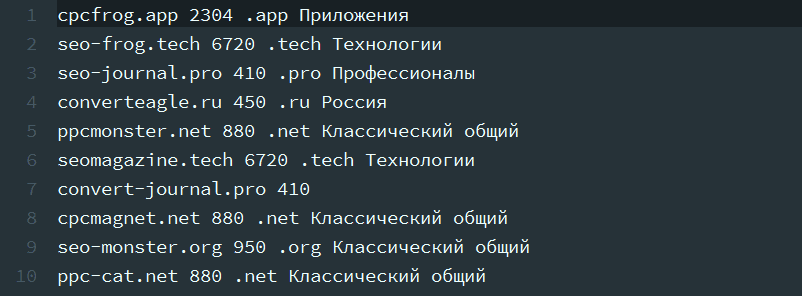
1-ая строчка в нашем файле кончается на английскую букву (доменной зоны) , а последующая за ней строчка начинается с числа (цены) – надобно убрать переносы строк.
Условие поиска: ([a-z]) rn( [0-9]) – обретаем латинскую букву в конце строчки r и цифру, с которой начинается новенькая строчка n, используем две пары запоминающих скобок.
Условие подмены: $1 $2 – результаты первых запоминающих скобок прибавляем ко вторым запоминающих скобкам через знак пробела.
Удаление переносов строк
4. Заменить пробелы на знаки табуляции.
Осталось заменить оставшиеся пробелы на знаки табуляции t.
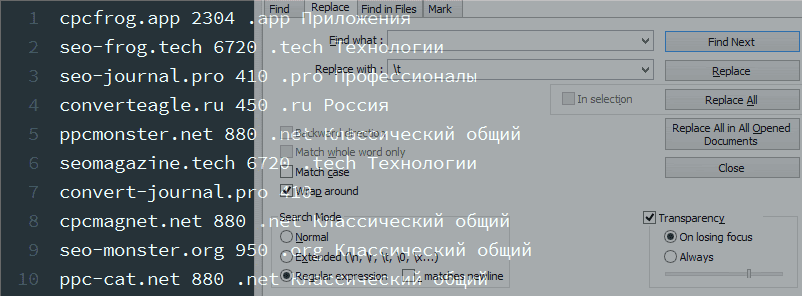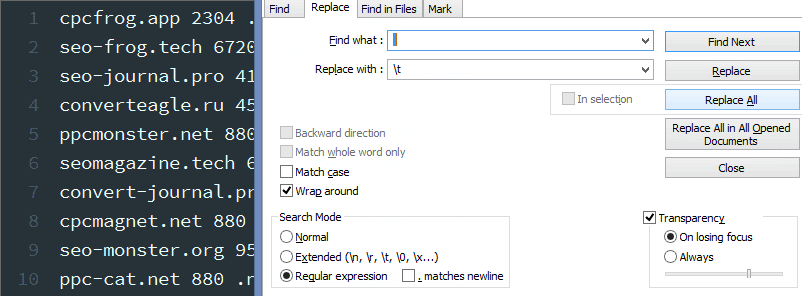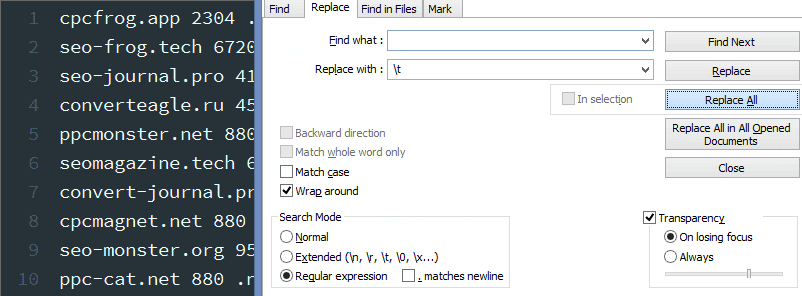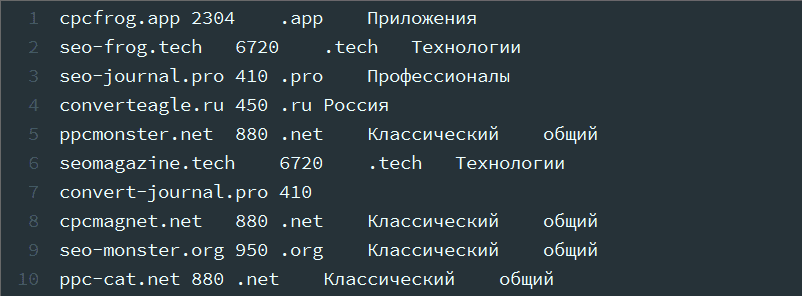
Подмена пробелов на табуляцию
Сейчас копируем и вставляем приобретенные результаты в электронную таблицу. Данные представляются корректно, с ими комфортно работать.
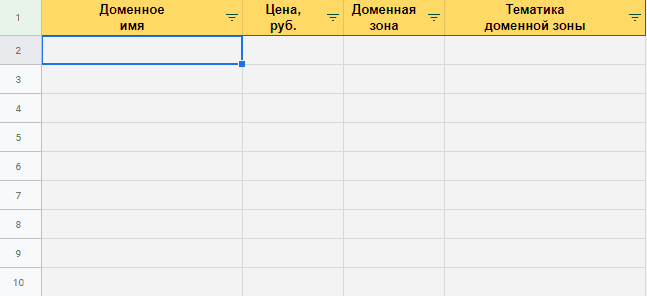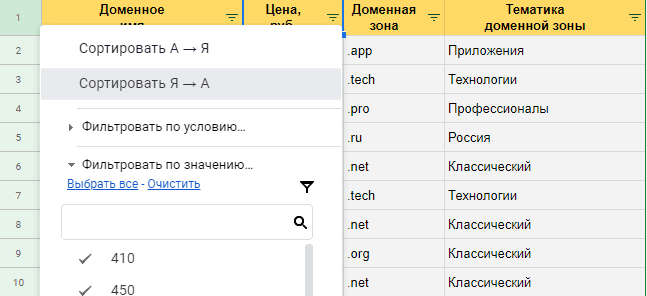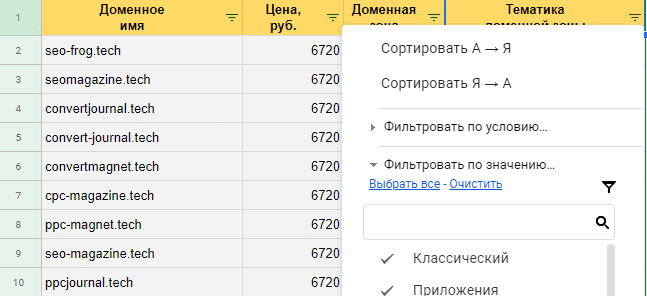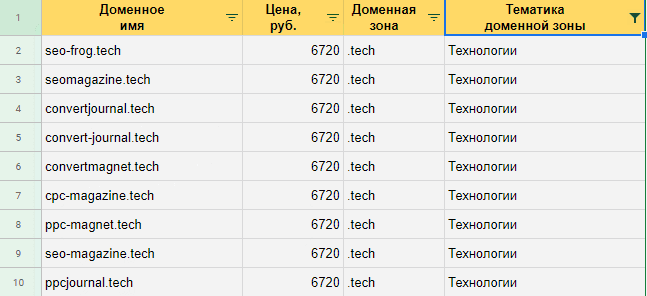
Данные в табличном виде
Outro
Не буду приводить длинноватого академического описания всех знаков – есть Wiki и много материалов, наиболее глубочайших и терминологически правильных, чем этот. Я желал только упростить трудное, заинтриговать, чтоб вы начали работать с регулярками.
Ежели вам стало занимательно – советую установить себе надстройку для Excel, скачать Notepad++, чтоб среда для работы с RegExp постоянно была под рукою. А ежели что-то не получится – есть сервисы для отладки, которые досконально обрисовывают работу вашего постоянного выражения посимвольно, что очень комфортно. Фортуны!

Комментариев 0