Логи сервера – недооцененный инструмент оптимизации сайта | SEO кейсы: социалки, реклама, инструкция
Внедрение журналов сервера дает больше способностей по сопоставлению с действием обыденного сканирования сайта. Файлы журналов сервера – единый достоверный источник, который указывает, как поисковые боты сканируют ваш сайт и каким образом это влияет на SEO.
Приобретенные данные можнож применять для улучшения характеристики сканирования сайта и общего уровня оптимизации поисковых машин проекта. Постоянный просмотр логов даст понимание, как прирастить рост позиций проекта в поисковой выдаче, общий размер трафика, количество конверсий и продаж.
Ах так расценивает значимость файлов логов сервера водящий аналитик компании Google Джон Мюллер:

Используя данные логов сервера, вы сможете проанализировать поведение поисковых роботов и ответить на главные для вас вопросцы. К образцу:
- Какие коды состояния страничек ворачиваются?
- Какие трудности с доступностью контента сайта были обнаружены во время сканирования?
- Какие типы страничек изредка навещают поисковые боты?
- Какие URL просматриваются почаще всего?
- Какие типы контента просматриваются почаще всего?
- О каких страничках сайта поисковые системы не додумываются?
- Отлично ли расходуется краулинговый бюджет сайта?
Это всего лишь несколько образцов, которые дает анализ логов сервера. У Google, как и у хоть какой иной поисковой системы, есть ограниченный бюджет сканирования. Но лишь правильные улучшения посодействуют сэкономить этот бюджет. Дадут возможность Google исследовать нужные странички сайта и навещать их почаще.
О том, что такое логи сервера и как их применять с выгодой для SEO, пойдет речь в данной статье.
Что такое логи сервера и для чего же они употребляются?
Логи сервера – файлы с веб-сервера, содержащие записи запросов (или «обращений») , которые получает сервер. Приобретенные данные хранятся неизвестно и содержат последующую информацию:
- время и дата, в которую был изготовлен запрос;
- IP-адрес запроса;
- запрошенный URL/контент;
- пользовательский агент.
Для унификации данных, приобретенных с различных версий серверов, записи логов умышленно запрограммированы для вывода в формате журнальчика консорциума W3C.
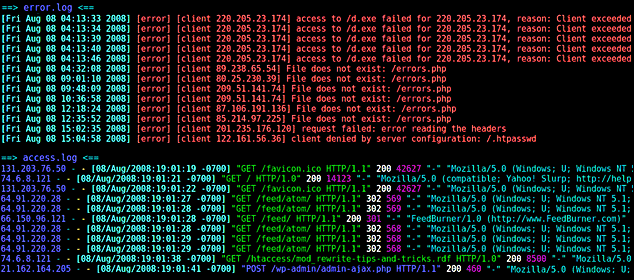
Структура строчки журнальчика почаще всего содержит обычный набор частей, которые предоставляют информацию о сеансе. Осмотрим для образца последующую запись:
127.0.0.1 – frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I;Nav) "
127.0.0.1 – имя удаленного хоста, IP-адрес.
frank – идентификатор юзера, запрашивающего страничку.
[10/Oct/2000:13:55:36 -0700] – дата, время и часовой пояс для конкретного запроса в формате strftime.
"GET /apache_pb.gif HTTP/1.0" – это одна из 2-ух команд (иная – «POST») , которую можнож выполнить. «GET» извлекает URL, а «POST» посылает что-либо, к образцу, комментарий на форуме. 2-ая часть – это URL, к которому исполняется доступ. Заключительная часть – версия HTTP, к которой исполняется доступ.
200 – код состояния документа, который был возвращен сервером.
2326 – размер в б документа, который был возвращен сервером.
"http://www.example.com/start.html" — заголовок HTTP-запроса «Referer». Это страничка, которая ссылается или включает в себя документ /apache_pb.gif.
"Mozilla/4.08 [en] (Win98; I;Nav) " — заголовок HTTP-запроса «User-Agent». Это информация, которую клиентский браузер извещает о себе.
Безусловно каждый запрос к содержимому вашего веб-сервера располагается в файле журнальчика. Это главно, потому что вы сможете точно созидать, какие ресурсы поисковые системы сканируют на сайте и какие трудности со сканированием появились или могут возникать.
Пример:.
В ходе анализа логов сервера 1-го из проектов на платформе WP была найдена неувязка – CMS генерировала великое количество «мусорных» страничек методом прибавления характеристик в URL-адреса главных версий. При всем этом данные странички не показывались в отчетах Google Search Console не были выявлены в ходе сканирования сайта десктопными парсерами. А вот Google нашел данные странички и добавил в индекс. Это привело к множественному дублированию контента и порожней растрате краулингового бюджета сайта. Записи логов сервера посодействовали выявить сходственные странички и ликвидировать механизм их генерации.
Доступность к просмотру логов сервиса дает возможность идентифицировать потенциальные «проблемные» странички. Анализировать необходимо последующие характеристики:
- Общее количество посещений страничек поисковыми роботами.
- Частота сканирования конкретной странички.
- Коды ответа сервера.
- Сканирование приоритетных и активных страничек.
- Внедрение ресурса бота и растрата краулингового бюджета.
- Дата заключительного сканирования страничек.
Доступ к файлам журнальчика сервера
Разные типы серверов берегут и правят своими файлами журналов по-разному. Не будем досконально вдаваться в процесс извлечения файлов журналов сервера, потому что он детально описан в документации к различным типам серверов.
Официальные управления по поиску и управлению файлами логов сервера:
- Доступ к файлам журнальчика Apache (Linux)
- Доступ к файлам журнальчика NGINX (Linux)
- Доступ к файлам журнальчика IIS (Windows)
Извлечение и обработка данных журнальчика сервера
Извлечение данных
Существует множество приборов для работы с файлами журналов сервера. Они имеют как идентичные типы приборов обработки и анализа, так и неповторимые функции –все зависит от цели работы с данными журналов. Ниже осмотрим более знаменитые посреди их.
При выборе сервиса для анализа логов главно знать разницу меж статическими приборами и приборами анализа в режиме настоящего медли.
1. Статические инструменты
Данный тип приборов дает возможность анализировать лишь статический файл. Главной недостаток – нет способности выбрать временной период предоставления данных. Чтоб проанализировать иной период, необходимо выгрузить новейший файл журнальчика.
Мой любимый инструмент для анализа статических файлов журналов – WebLog Expert. Это прыткий и сильный анализатор логов сервера:
Он предоставляет необъятную информацию о гостях вашего сайта: статистику активности, доступ к файлам, пути перехода на сайт, информацию о ссылающихся страничках, поисковых системах, браузерах, операционных системах и почти все иное. WebLog Expert может анализировать логи веб-серверов Apache, IIS и Nginx. Он может читать форматы сжатых файлов журналов GZ и ZIP, потому вам не надо распаковывать их вручную.
Более знаменитый и сильный инструмент для анализа логов сервера – Screaming Frog Log File Analyzer. Включает в себя все функции предшествующего сервиса. Но имеет более эластичный функционал по доли удобства анализа данных логов сервера и формирования отчетов. Дает возможность импортирования перечня URL-адресов, к образцу, из файла sitemap.xml веб-сайта, и сравнения их с данными файла логов сервера. Это подсобляет отыскать потерянные или безызвестные странички, которые Googlebot не просканировал.

Посреди иных статических приборов анализа данных журнальчика сервера можнож выделить:
- Log Analyzer: Trends – позволяет анализировать конфигурации главных характеристик веб-сайта как графически, так и численно. Программное обеспечение дает более 20 обычных отчетов, которые включают отчеты «Хиты», «Неповторимые посетители», «Посещенные страницы», «Ссылающиеся сайты», «Поисковые фразы», «Переходы» и отчеты с внедрением иных характеристик веб-сайта.
- Web Log Explorer – поддерживает более 43 форматов файлов журналов. Может автоматом распознавать форматы логов сервера, извлекать сжатые файлы журналов, обрабатывать несколько файлов журналов и загружать журнальчики из различных источников: локальных или сетевых источников, FTP или базы данных через ODBC. Web Log Explorer может читать самые знаменитые форматы сжатых файлов журнальчика: BZIP2, GZIP, ZIP, 7z, rar и другие – их не надо распаковывать вручную.
2. Приборы анализа в режиме настоящего времени
Данный тип приборов дает прямой доступ к журнальчикам сервера. Сервисы данной группы инсталлируются в программную среду сервера и мониторят в режиме онлайн все доступные конфигурации. Преимущество – возможность выбрать хоть какой просвет медли для анализа данных.
Анализ и визуализация данных нисколечко не уступают, а в неких вариантах и превосходят статические приборы.
Посреди приборов анализа журналов сервера в режиме настоящего медли можнож выделить:
- GoAccess – сервис был спроектирован как прыткий анализатор логов на базе терминалов. Его главная мысль содержится в том, чтоб живо анализировать и просматривать статистику веб-сервера в режиме настоящего медли без необходимости применять браузер. GoAccess может генерировать полный автономный отчет в настоящем медли в формате HTML, также JSON и CSV отчеты.
- Logstash – инструмент обработки данных на стороне сервера с открытым начальным кодом, который сразу получает данные из множества источников. Подходит для сбора данных журналов сервера, их хранения и анализа.
- Splunk – программное обеспечение сотворено для помощи процесса индексации и дешифрования журналов хоть какого типа, будь то структурированные, неструктурированные или трудные журнальчики прибавлений.
- Octopussy – менеджер журналов, основанный на Perl. Его главная функциональность содержится в анализе журналов, творении отчетов на базе данных журналов и предостережении администрации о хоть какой подходящей инфы.
- Seolyzer – гибкая система, которая дозволяет контролировать множество характеристик сайта в режиме настоящего медли. Благодаря анализу логов Seolyzer.io вы сможете безотлагательно реагировать на делему, которая влияет на оптимизацию поисковых машин проекта.
3. Обработка и анализ данных в среде Microsoft Excel (Google Spreadsheet)
Практически, данный метод можнож отнести к статическим приборам анализа данных логов сервера. Но потому что он кардинально различается от статических сервисов по способу извлечения и обработки данных, то я решил этот метод вынести в отдельный пункт.
Это сразу самый обычный и самый времязатратный метод анализа логов сервера. У данного метода есть один значимый недостаток – количество анализируемых строк ограничено ресурсами вашего компа. Решить данную делему можнож методом разбиения начального файла на несколько долей. К превосходствам относится наисильнейший функционал по доли статистической обработки данных, который недоступен для перечисленных выше сервисов.
Метод событий при использовании данного метода последующий:
- Конвертировать.log в.csv.
Когда вы извлечете журнальчик веб-сервера, получите файлы с расширением.log. Преобразовать их в формат, понятный для Excel, очень просто: выберите файл и введите расширение файла как.csv. Excel откроет файл, не испортив содержимое.
- Преобразовать строчки в столбцы.
Открытие в Excel традиционно приводит к тому, что данные журнальчика сервера записываются в один столбец. Чтоб упорядочить набор данных в управляемый формат, необходимо распланировать данные по нескольким столбцам. Для удобства воспользуйтесь функцией «Текст в столбцы»:

- Определиться с размером подборки.
Открыв файл в Excel, проверьте, сколько строк данных в нем содержится. Превосходный размер выборки/диапазон для работы – 60–120 тыс. строк. При большем объеме подборки данных Excel может закончить отвечать на запросы, как вы начнете фильтровать, сортировать и сочетать комплекты данных.
В итоге вы получите набор данных о посещениях страничек вашего веб-сайта:

Анализ данных
Опосля извлечения и расшифровки всех данных файла логов сервера можнож приступать к главной цели всего этого процесса – анализу посещений страничек сайта.
!Основное правило – перед началом необходимо определиться с главной целью анализа. В неприятном случае высока возможность загрузнуть в громадных массивах данных не получить никакой выгоды.
!2-ой момент – не пренебрегайте отсортировать свои данные с поддержкою пользовательского агента. Анализируя Googlebot для компов, Googlebot для телефонов и Yandexbot совместно, вы не отыщите никакой полезной инфы.
!Последнее – проверьте, вправду ли вебсканер является Гуглботом. Или это замена личности от спам-ботов и скреперов?Чтоб проверить, вправду ли веб-сканер, обращающийся к вашему серверу, является роботом Google, запустите обратный поиск DNS, а позже прямой поиск DNS. Доскональный метод событий описан в Справочном центре Google для веб-мастеров.
Последовательность анализа
Вариантов быть может множество. Все зависит от выбранной цели анализа. Разные сценарии анализа – это контрольный чек-лист при работе со перечнем просканированных страничек. Осмотрим более знаменитые из их.
Частота сканирования определенным агентом пользователя
Творение сводной таблицы и диаграммы на базе характеристики timestamp (date) и фильтрации с поддержкою определенных пользовательских агентов. Для компов используйте Googlebot, для телефонов Googlebot, Googlebot Video, Googlebot Images и т.д. (полный перечень юзер-агентов поисковых роботов Google доступен по ссылке) . Это быть может очень полезно для прыткого выявления аномалий с конкретными пользовательскими агентами поисковой системы.
Дата заключительного сканирования страницы
Анализ файла журнальчика извещает, когда Google сканировал определенную страничку в заключительный разов. Таковым образом, можнож оценить, как живо обновленный контент предопределенной странички переиндексируется.
URL-адреса, которые почаще и реже всего сканируются поисковым роботом
Анализ количества посещений конкретных страничек дозволяет узреть, где поисковые системы проводят великую часть собственного медли при сканировании, также сегментировать области, которые стали реже всего обходиться роботом. Просмотрев данные, можнож найти типы URL, которые поисковым сканерам просто не необходимы (так именуемые, отходы сканирования) . Анализ журналов также поможет найти более знаменитые странички. Таковым образом можнож выяснить, являются ли более навещаемые ботом странички главными исходя из убеждений оптимизации поисковых машин сайта. Это дозволит недопустить игнорирования неких страничек или отдельных разделов сайта.
Пример: В ходе анализа оптимизации поисковых машин проекта была найдена неувязка со сканированием и индексацией страничек фильтров. Логи сервера проявили, что Гуглбот навещает их реже сходственных типов страничек. Опосля оптимизации внутренней перелинковки фильтровых страничек с более нередко навещаемыми разделами сайта их ценность возросла – Гуглбот стал почаще исследовать фильтровые странички.
HTTP-ответ сервера
Сегментация по ответу заголовка сервера дозволяет живо оценить оплошности сканирования, с которыми сталкиваются поисковые системы. Подборка из URL-адресов и кодов ответа сервера покажет, с какими оплошностями сталкивается поисковая система. Схожи ли они при сканировании определенного URL-адреса или целого спектра однотипных страничек. Понимание трудности даст возможность скорректировать стратегию устранения сходственных ошибок.
Более нередко встречаемые ответы сервера при анализе журналов:
- 500 – Ошибка сервера.
- 404 – Страничка не найдена.
- 302 – Временное перенаправление.
- 301 – Неизменный редирект.
Время, затраченное на сканирование
Анализ медли, затраченного на сканирование странички (измеряется в миллисекундах) , указывает, какие запрошенные URL-адреса в среднем были загружены быстрее/медленнее. Соединение этих URL-адресов по каталогам дозволит измерить производительность по разделам сайта с целью выявления менее производительных.
Типы файлов
Анализ типов файлов дозволит найти, доступны ли для сканирования Гуглботом, к образцу, нужные CSS/JS файлы или есть трудности с их доступностью. В то же время данный параметр покажет, не сканируются ли негодные форматы файлов, расходуя при всем этом краулинговый бюджет сайта.
Оценка краулингового бюджета
Анализ журналов сервера также подсобляет найти, как расходуется бюджет сканирования. К образцу, расходует ли Google очень много медли на сканирование изображений.
Краулинговый бюджет связан с авторитетом домена, оптимизацией сайта и пропорционален ссылочной массе проекта.
Пример: В ходе анализа логов сервера большого ecommerce-проекта было найдено, что треть краулингового бюджета сайта тратится на обход негодных страничек, содержащих каноническую ссылку на главные версии страничек сайта. Данная ссылка была расположена в коде, определялась в ходе парсинга сайта десктопными сканерами, но не распознавалась Гуглботом. При всем этом странички добавлялись в индекс поисковой системы, генерируя дубли. Выявление и устранение предпосылки нераспознавания поисковым ботом канонической ссылки решило делему, позволив применять ценный краулинговый бюджет для сканирования более приоритетных страничек сайта и устранив дублирование контента.
Ежели боты встречают очень много негативных причин, связанных с внутренней и технической оптимизацией сайта, они не будут ворачиваться так нередко, и бюджет сканирования будет тратиться на негодные странички. Ежели у вас есть опять сделанные странички, которые вы желаете проиндексировать, но краулинговый бюджет был истрачен впустую на сканирования негодных страничек, Google не увидит их.
Это далековато не полный перечень сценариев анализа данных логов сервера. Объедините журнальчики сервера с иными источниками данных. Это откроет новейший уровень понимания контекста логов сервера, который может не отдать анализ лишь данных журналов. Совместите журнальчики сервера с иными источниками: данными Google Analytics, отчетами Search Console по индексации/ключевым словам/кликам/показам, xml-картами сайта, данными сканирования сайта Netpeak Spider или Screaming Frog и начинайте задавать вопросцы:
- Какие странички не включены в sitemap.xml, но сканируются поисковыми роботами?
- Какие странички включены в файл Sitemap.xml, но не сканируются?
- Нередко ли сканируются странички, приносящие конверсии?
- Большая часть просканированных страничек находятся в индексе?
- Сканируются ли странички, заблокированные в Robots.txt?
Плацдарм для анализа данных безграничен. Все зависит лишь от ваших целей и наличия данных. Вы сможете быть удивлены находками, которые вы обнаружите в итоге.
Комментариев 0