Несколько способов парсинга данных | Статьи SEOnews

Данная статья написана по следам воркшопа «Начало начал и база основ – секреты парсинга» от Сергея Горобий, управляющего отдела аналитики SEOWORK.
Что это такое и для чего же?Парсинг vs Скрапинг vs Краулинг
Парсинг – это структуризация и синтаксический разбор неструктурированных данных. Краулинг – это обход страничек сайта и сбор неструктурированных данных. Скрапинг – соединяет в себе 1-ые 2 понятия: это и обход ссылок, и сбор данных, также разбор и структуризация.
В SEOWORK вы сможете встретить парсинг при сборе:
- частотности запросов (парсинг Wordstat) ;
- поисковой выдачи (мы забираем данные про сниппеты, колдунщики, все данные про органику и контекстную рекламу) ;
- слепков HTML и их разбора в «Аналитике»;
- данных в «Тех мониторе»;
- результатов для большинства «инструментов»;
- данных с наружных источников (системы аналитики, Вебмастера и т. д.) ;
- данных для творения частей.
Как можнож парсить данные?
Вручную в браузере. Вы сможете применять для этого расширения, такие как Scraper, Data Scraper. Этот метод подходит для маленького количества страничек.
Используя десктопные приложения. Для 1000 и наиболее страничек посодействуют приборы Screaming Frog, A-Parser, Content Downloader.
С поддержкою надстройки в Excel ( ParserOK) .
Прямым парсингом в Google Таблицы ( функции IMPORTXML и IMPORTHTML) .
И еще много иных способов и парсеров (см. статью) .
Синтаксический анализ HTML
Когда мы парсим данные, нередко нам не требуется забирать весь HTML со всей структурой и разбирать его полностью. На стартовом шаге мы желаем отобрать определенные данные из каких-либо определенных зон документа и в этом нам подсобляют селекторы. Они обращаются к конкретной зоне и адресу структуры и забирают лишь нужные нам данные.
1. Самые знаменитый – CSS selector (CSSPath)
CSSPath = ‘html > body > span:nth-of-type( 1) a’
За счет прописанных стилей селектор избирает нужные блоки из структуры документа и теснее с их конфискует данные.
2. Xpath selector (удобное расширение для браузера)
Xpath = ‘html/body/span[1]//a’
Вначале употреблялся для xml, но также актуален и для html-структуры. В отличии от CSS-селектора он может обращаться в глубину и обратно – можнож провалиться в родительскую ноду/элемент и опосля возвратиться обратно. Он преимущественнее, потому что это передвижение по осям накрывает множество потребностей для парсинга.
3. jQuery selector
XPath
Работать с XPath можнож через copy XPath конкретно через интерфейс браузера, но лучше прописывать путь XPath без помощи других. Казалось бы, что копировать путь – довольно для получения нужных данных, но как указывает практика, без синтаксиса все одинаково не обойтись.
Потому давайте разберем синтаксис XPath подробнее.
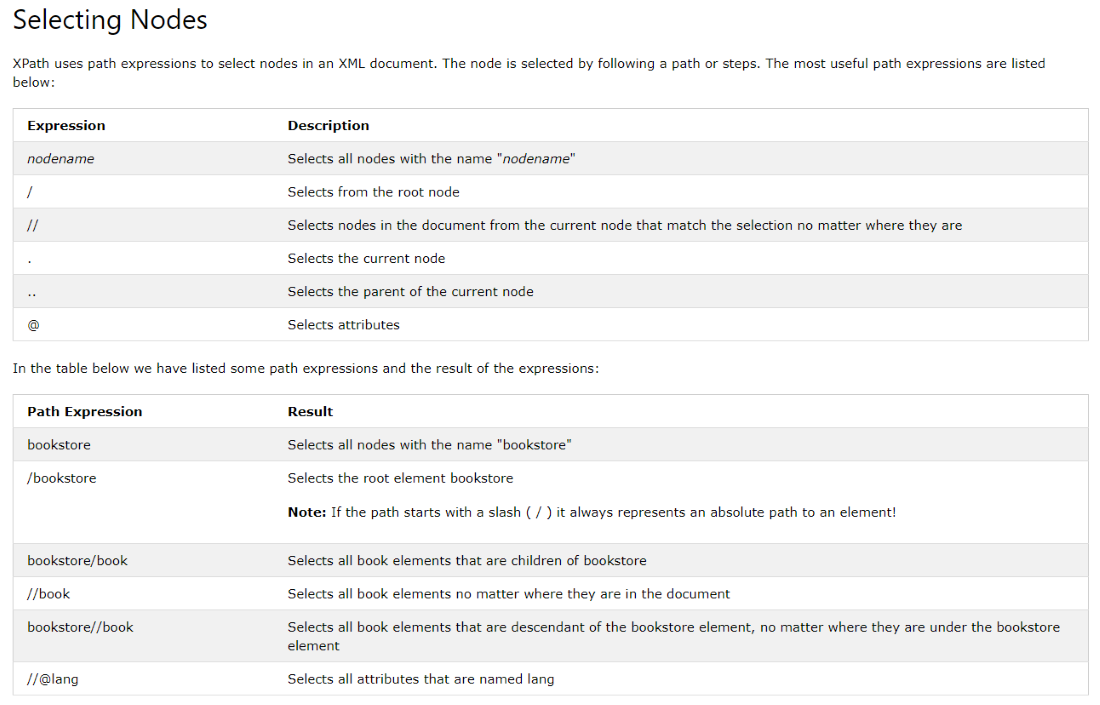
Для работы с XPath мы используем ноды (ссылка) :
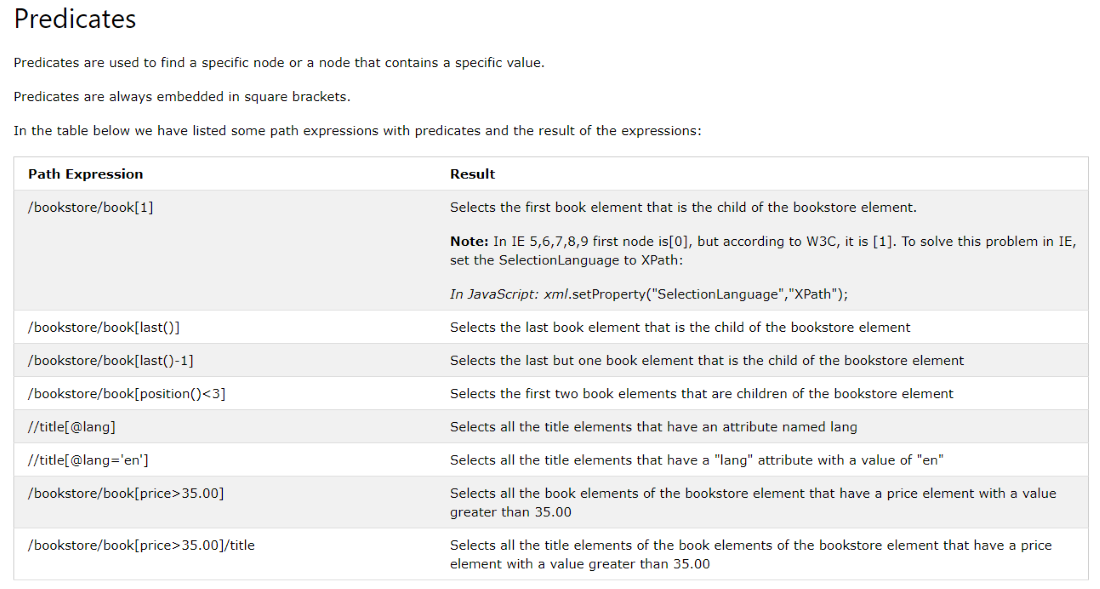
предикаты (ссылка) :
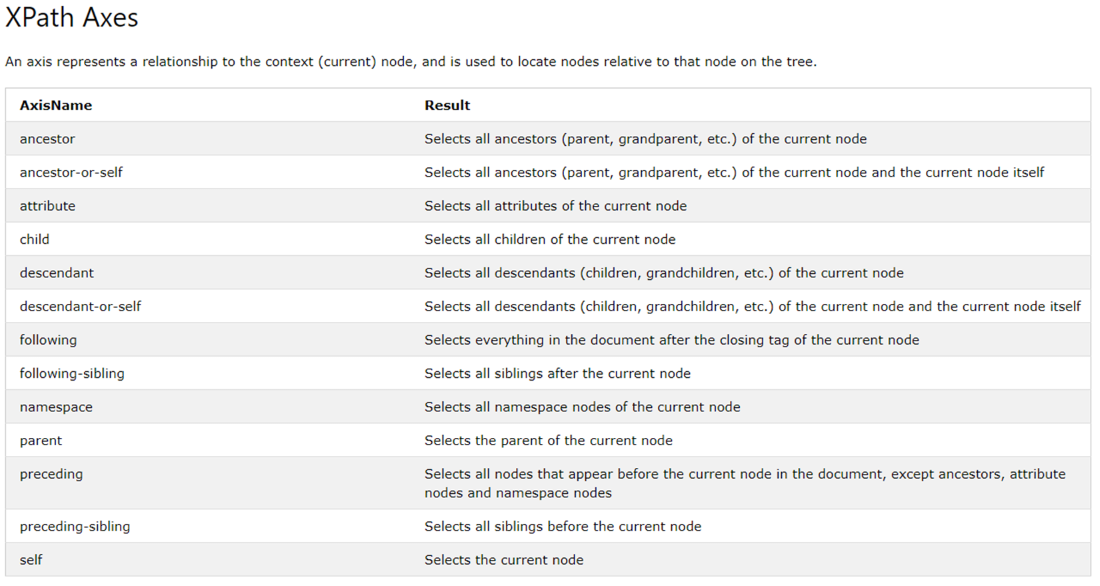
Оси ( ссылка) :
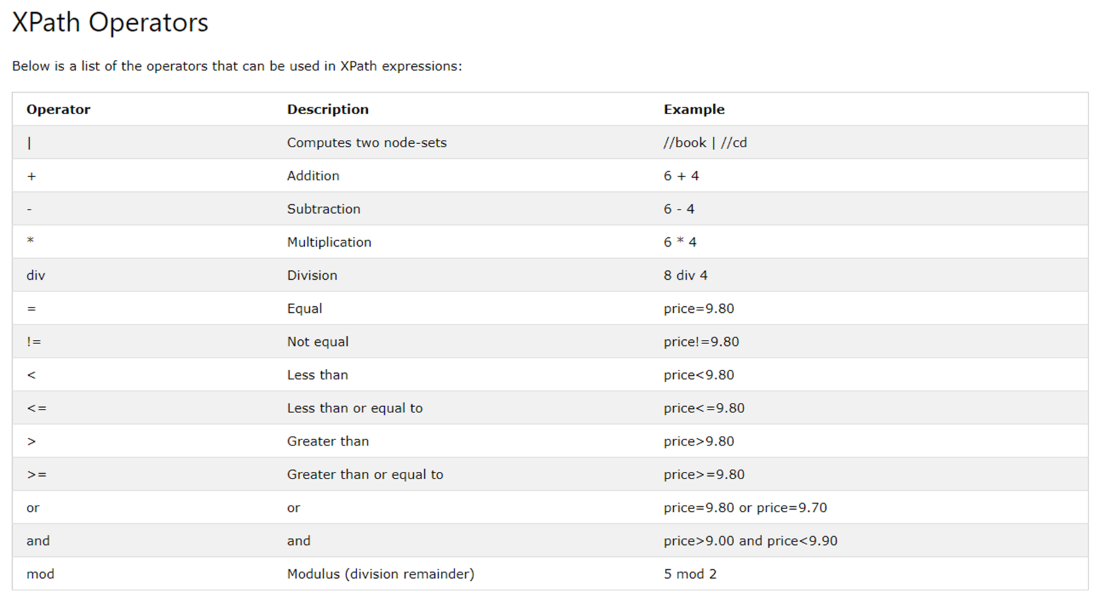
а также операторы (ссылка) :
Функции
Облегчить работу с данными можнож еще на шаге подготовки к парсингу, используя функции XPath.
Главные полезные функции:
- count() ,
- last() / position() ,
- string-length() ,
- contains() ,
- starts-with() либо ends-with() ,
- boolean() ,
- substring-before() либо substring-after() ,
- normalize-space() .
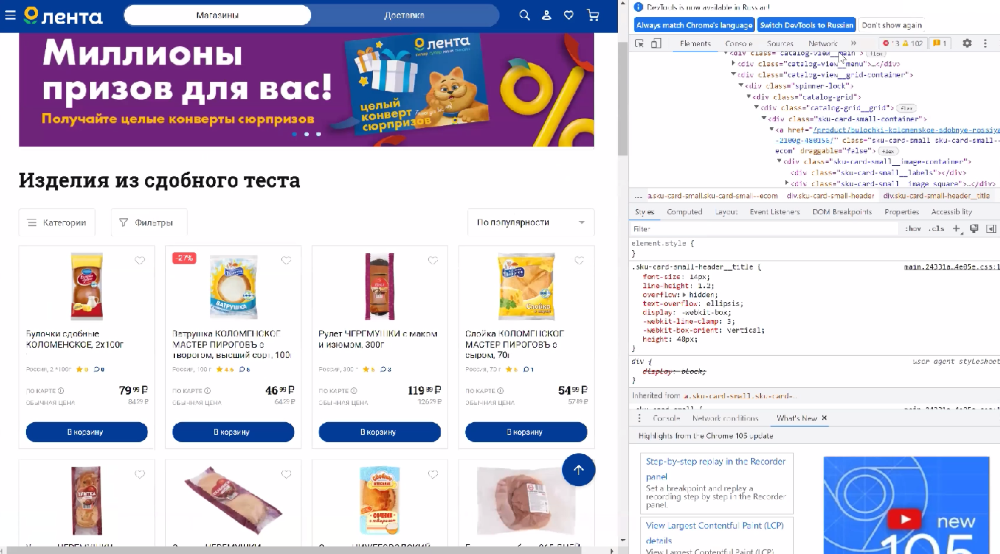
Задачка #1. Смонтировать с листинга все ссылки на продукты, которые стоят больше 50 руб.
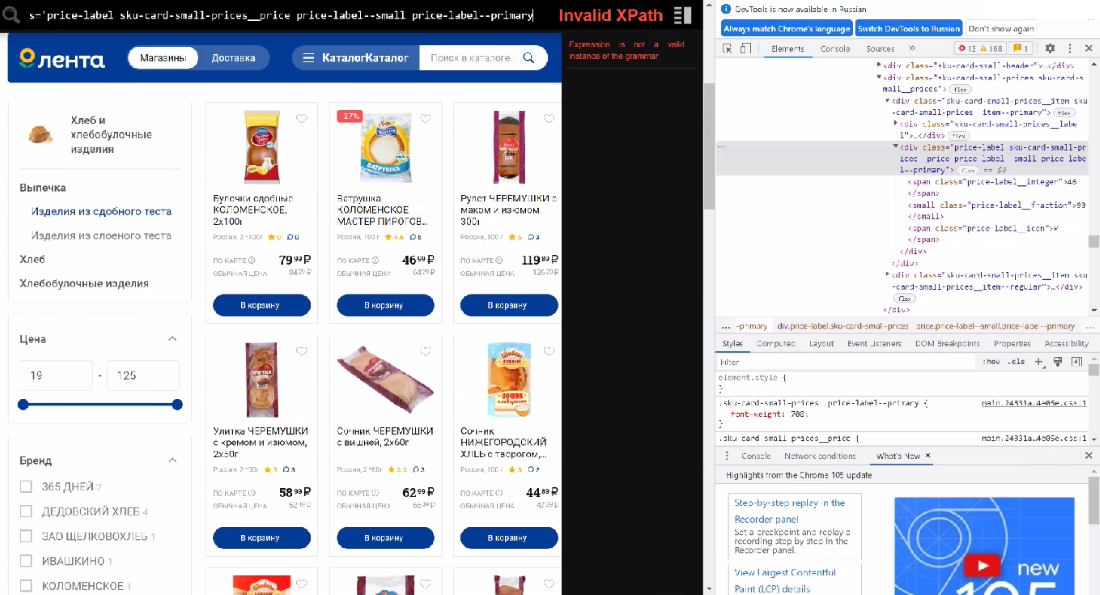
Сходу на страничке мы обретаем лейб цены и обращаемся к этому графу. Нам занимательны лишь целочисленные значения, избираем их через span и означаем позицию предикатом.
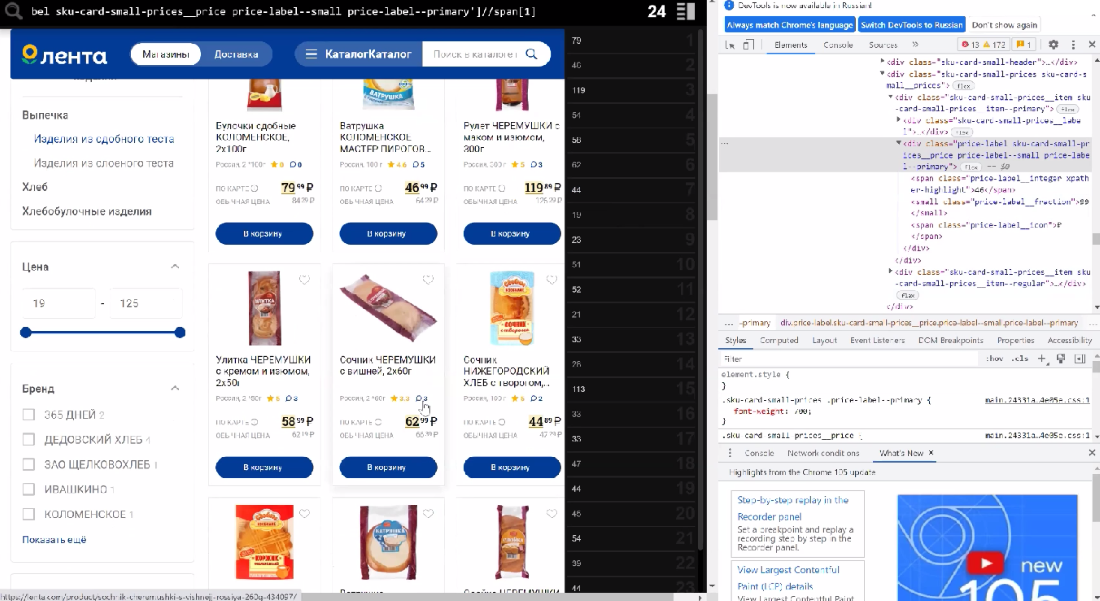
И здесь же мы можем ограничить вывод данных через какое-то условие, к примеру, больше 50 руб. Обращаемся к ноде через точку и задаем условие.
Страничка, на которой работал: https://lenta.com/catalog/hleb-i-hlebobulochnye-izdeliya/vypechka/izdeliya-iz-sdobnogo-testa/
Xpath //div[@class='price-label sku-card-small-prices__price price-label--small price-label--primary']//span[1][.>50]
Как вы видите, в out выводятся пока лишь числа. Как достать ссылки продуктов?Обратимся к структуре и увидим, что ссылка находится по структуре выше, чем div.
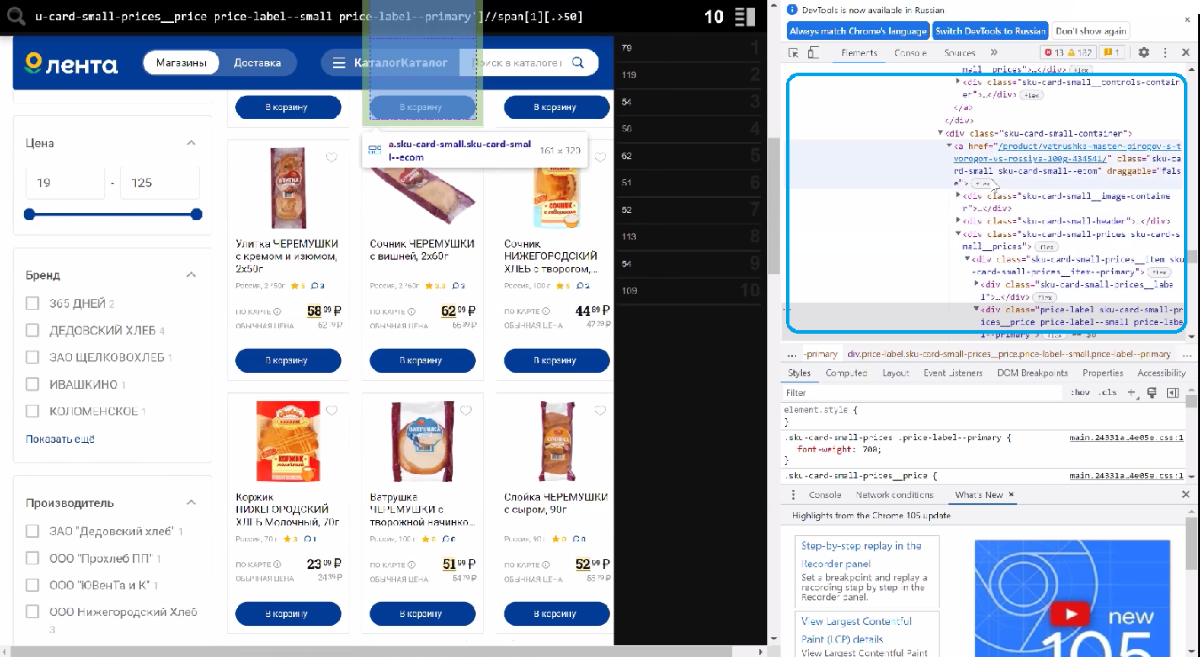
Другими словами наша стоимость вложена в эту ссылку, и потому что мы используем XPath, мы можем передвигаться по оси вверх и вниз. Обратимся к элементу предку, используем ось ancestor и забираем атрибутом href у частей a.
В итоге для странички: https://lenta.com/catalog/hleb-i-hlebobulochnye-izdeliya/vypechka/izdeliya-iz-sdobnogo-testa/ получаем Xpath
//div[@class='price-label sku-card-small-prices__price price-label--small price-label--primary']//span[1][.>50]//ancestor::a/@href
Задачка #2. Подсчет количества продукта на странице
Разберем функцию “count” – функция подсчета. К примеру, мы избрали все продукты на страничке и желаем посчитать их количество на страничке.
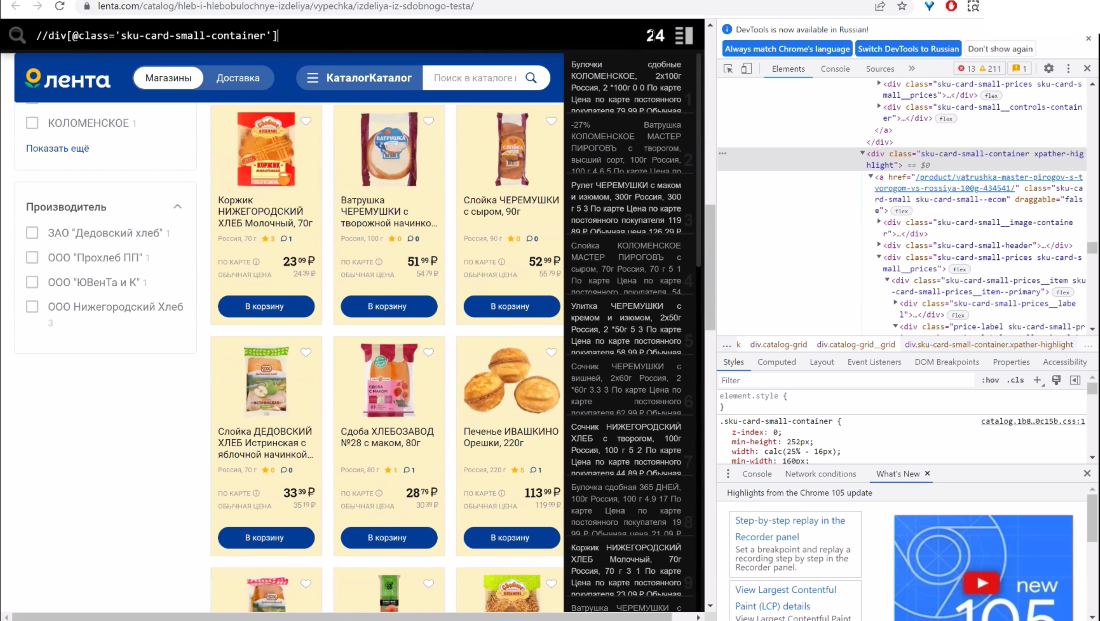
В итоговом файле у нас будут лишь все текстовые значения, которые выведены в блоке справа, а мы желаем получить конкретно цифровое значение. Потому прописываем функцию count и получаем необходимое нам значение количества.
Страничка, на которой работал: https://lenta.com/catalog/hleb-i-hlebobulochnye-izdeliya/vypechka/izdeliya-iz-sdobnogo-testa/
Xpath: count( //div[@class='sku-card-small-container'])
Задачка #3. Как посчитать количество знаков в статье
Обретаем в структуре элемент, в каком размещается вся статья, в нашем случае обращаемся к div с атрибутом itemprop со значением articleBody.
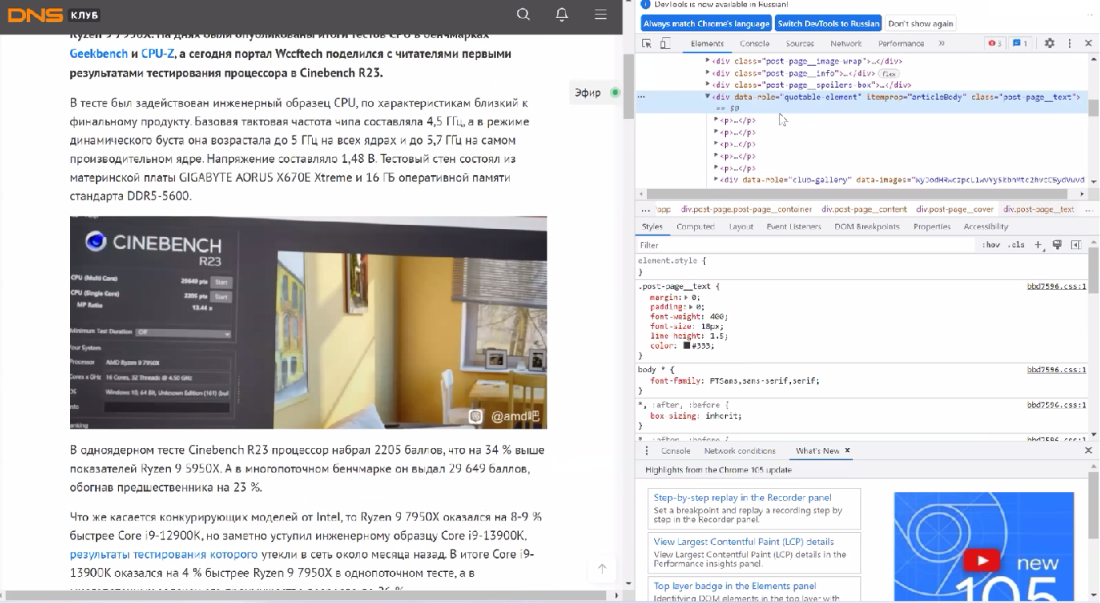
Выделили в граф весь текст статьи и переходим к подсчету количества знаков, используя функцию string-length.
Страничка, на которой работал: https://club.dns-shop.ru/digest/78762-ryzen-9-7950x-okazalsya-do-26-medlennee-core-i9-13900k-v-cinebe/
Xpath: string-length( //div[@itemprop='articleBody'])
Задачка #4. Смонтировать все ссылки на один тип товара/страницы с общей странички витрины/листинга
Последующая нужная функция – contains. По ней можнож выискать разные элементы, которые содержат, к примеру, определенный текст. Разберем на образце Окко.
У нас есть страница-коллекция, и мы желаем отобрать с нее все линки карточек кинофильмов, не затрагивая карточки, в каких размещаются телесериалы.
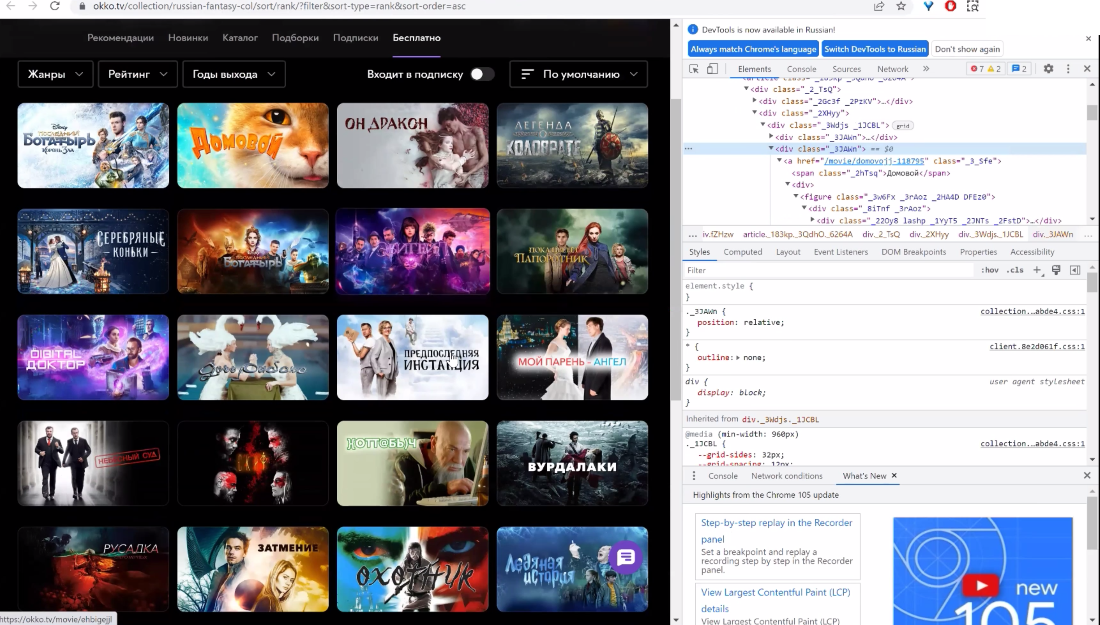
Для начала обратимся к графу всех карточек в верхнем уровне, избираем этот граф. Вышло 20 карточек (отмечаем, что есть url 2-ух структур – movie и serial, по ним и будем разграничивать киноленты и телесериалы) . Опосля чего же обращаемся к линкам и задаем нужные условия (фильтрация по movie) .

Страничка: https://okko.tv/collection/russian-fantasy-col
Получаем: //div[@class='_3JAWn']//a[contains( @href, '/movie/') ]/@href
По итогу видим, что в выборке остается 16 карточек кинофильмов.
Задачка #5. Фильтрация по тексту
Также можнож обращаться просто к анкору ссылки. Здесь мы найдем пример на сайте Ленты.
Страничка: https://lenta.com/catalog/hleb-i-hlebobulochnye-izdeliya/vypechka/izdeliya-iz-sdobnogo-testa/
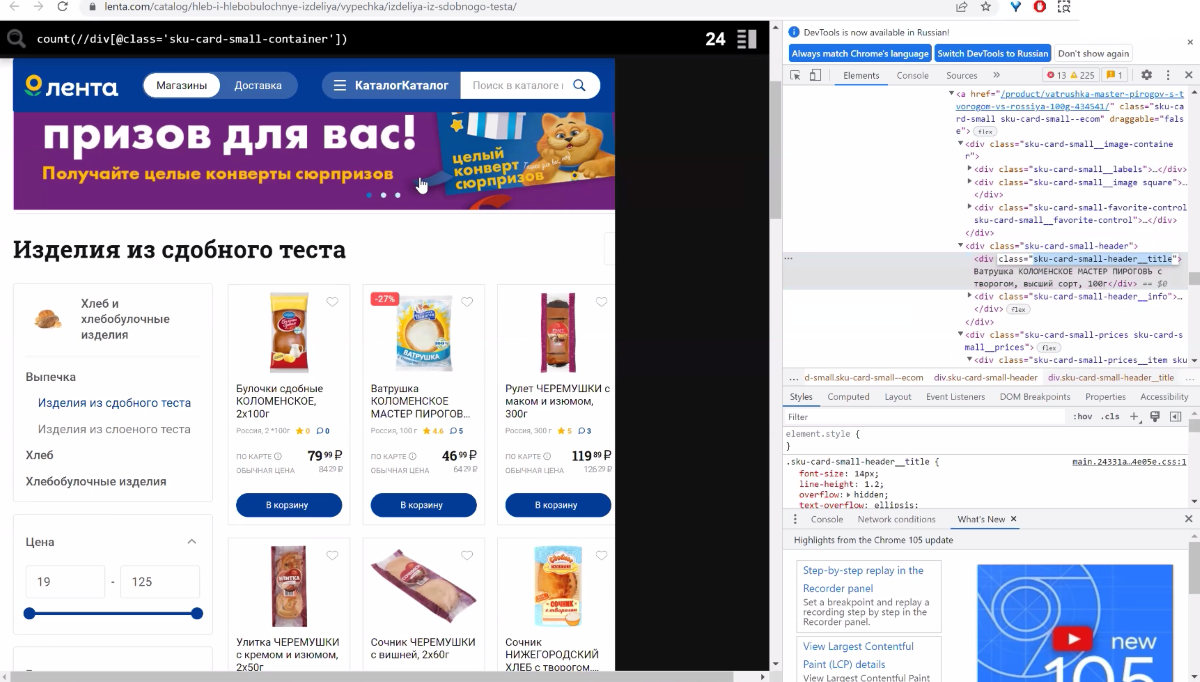
Найдем на листинге div с заглавием карточек и отфильтруем по наименованию. Прописываем «A»-предикат, через точку обращаемся к самой ноде и теснее здесь задаем, какое заглавие нам необходимо, к примеру, «Ватрушка».
//div[@class='sku-card-small-header__title'][contains(., Ватрушка) ]
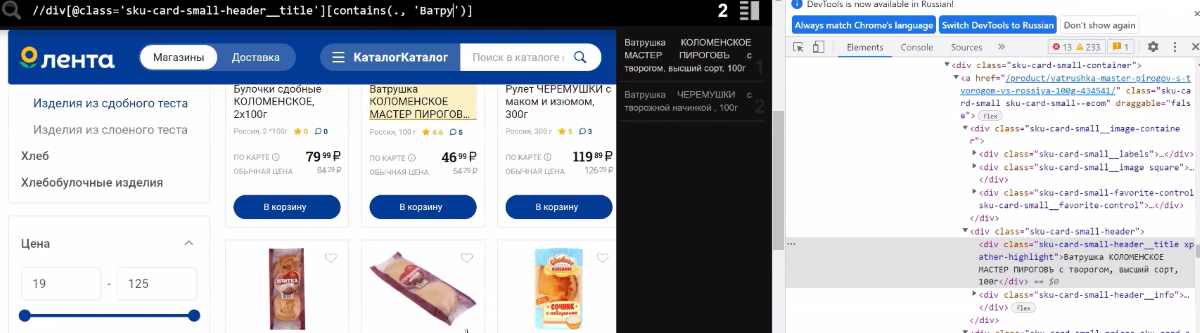
Обретаем 2 пригодных продукта.
Задачка #6. Поиск частей, которые начинаются либо кончаются с подходящего значения
Далее остановимся на функции starts-with() либо ends-with() . На образце, который мы осматривали на сайте Окко, мы можем заменить функцию contains и задать starts-with. Это будет значить, что строчка обязана начинаться с movie.
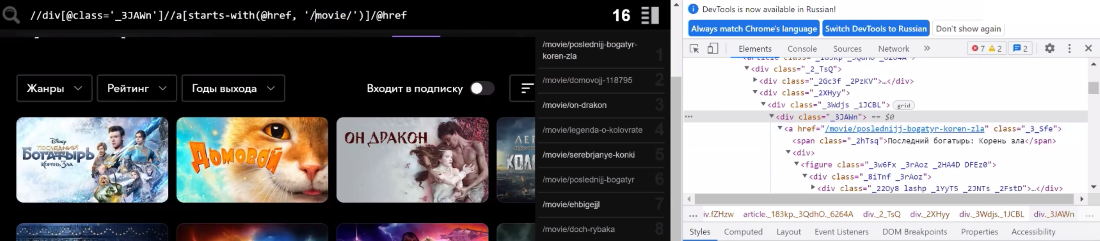
Страничка: https://okko.tv/collection/russian-fantasy-col
Получаем: //div[@class='_3JAWn']//a[starts-with( @href, '/movie/') ]/@href
Задачка #7. Дублируются ли заглавия H1 на страничке?
Функция boolean дает бинарное значение true/false на данное нами условие. К примеру, есть задачка отыскать странички, где могут дублироваться несколько H1. Ежели вы отыскали их на некий страничке и желаете убедиться, что на иных страничках сайта таковой трудности нет – это просто сделать через функцию boolean.
Прописываем условия, что на страничке наиболее 1 заголовка H1, и на выходе получаем false либо true.

Страничка: https://market.yandex.ru/catalog--noutbuki/54544/list
Получаем: boolean( count( //h1) >1)
Ежели на страничке H1 не дублируется и лишь один, то в out мы будем получать false. Ежели же H1 на страничке несколько, то в out мы получим true.
Задачка #8. Выяснить количество продуктов на листинге + отсекаем текст
Чтоб выяснить количество продуктов на листинге, когда нет способности посчитать все продукты в категории (к примеру, много страничек пагинации) , можнож пользоваться лайфхаком и отыскать значение количества продуктов на первой страничке листинга. В нашем кейсе мы отыскали это значение под всеми фильтрами. Видим, что в категории конструкторы – 9526 продуктов. Можем достать Xpath этого элемента.
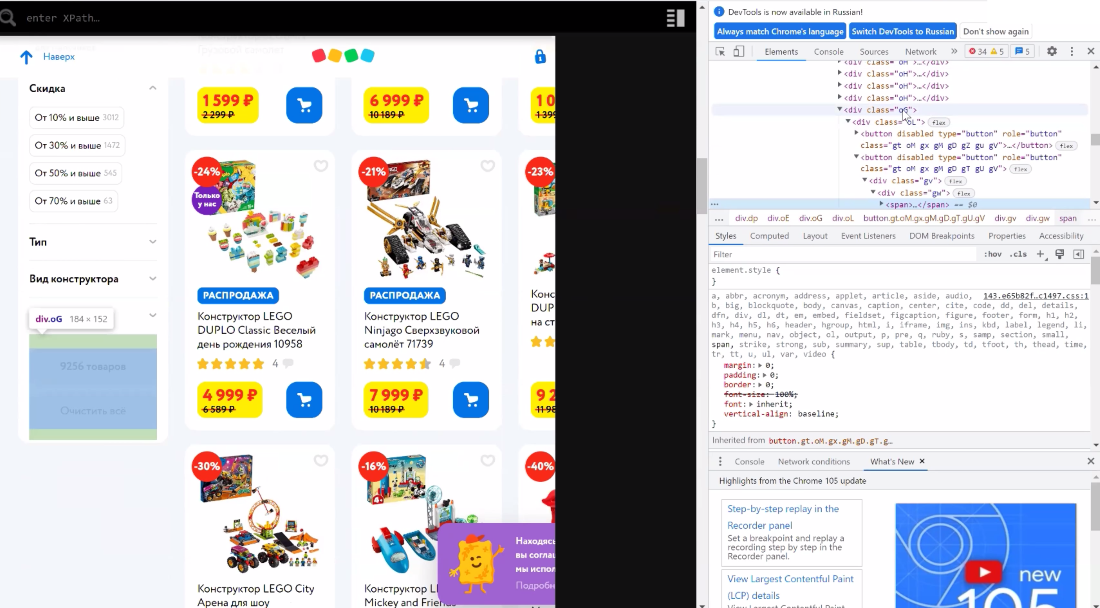
Страничка: https://www.detmir.ru/catalog/index/name/konstruktory/
Xpath: //div[@class='wQ']//button[2]
Но мы видим в нашем out текст «9526 товаров». Воспользовавшись функцией substring-before() , мы можем отсечь значение “ товаров” и в out получим лишь число 9526.
Страничка: https://www.detmir.ru/catalog/index/name/konstruktory/
Xpath: substring-before( //div[@class='wQ']//button[2], ' товаров') //итоговый запрос//
Задачка #9. Как смонтировать значения без излишних пробелов?
К примеру, мы планируем спарсить все H1, но откуда-то возникли странноватые пробелы. Поправить ситуацию живо можнож функцией normalize-space() .
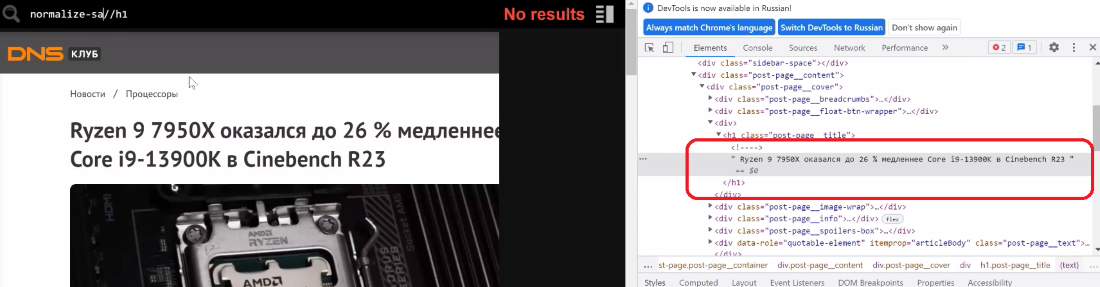
Для этого прописываем xpath normalize-space( //h1) .
Задачка №10. Как смонтировать ссылки на изображения?
На образце МВидео соберем ссылки на все изображения с листинга. Обретаем нужный DIV на страничке, настраиваем фильтрацию по размеру рисунки и на выходе получаем весь перечень картинок.
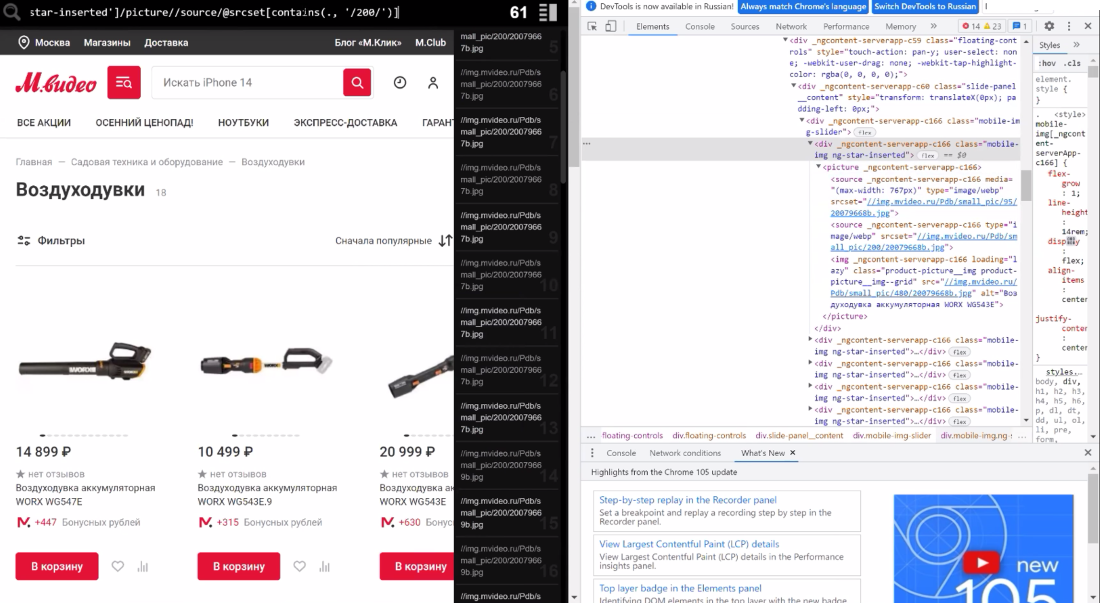
Страничка, на которой работал: https://www.mvideo.ru/sadovaya-tehnika-i-oborudovanie-8027/vozduhoduvki-9489
Xpath //div[@class='mobile-img ng-star-inserted']//picture//source/@srcset[contains(., '/200/') ]
и //div[@class='mobile-img ng-star-inserted']//picture//img/@src
Еще более образцов работы с XPath вы узнаете из воркшопа «Начало начал и база основ – секреты парсинга».
Статьи
Комментариев 0