Как Netpeak Spider подсобляет дополнять автотесты, выискать баги и оплошности | Статьи SEOnews
Партнерский материал

Кейс будет полезен тем, кто желает непрерывно мониторить наличие заморочек, а необыкновенно в тот момент, когда Product-отдел их вовсю плодит.
Определите пул страничек для отслеживания
Тут главно найти не количество страничек, а их тип и обилие. Например, ежели у вас на сайте находятся такие типы страничек как:
То вам наверное приходилось сталкиваться с последовательной выкаткой этих самых страничек в релиз или теснее в live-режиме (часто это все делается по неизвестной никому причине в пятницу часов так в 6–7 вечера) , чтоб днем в пн SEO-специалист не расслаблялся. Да и кто ему даст, ежели теснее на выходных он видит просадку?
В процессе сбора страничек для отслеживания главно еще осмысливать, что ежели сайт мультиязычный, то необходимо также включать странички языков, которые являются приоритетными. Например, мы отслеживанием лендинги, странички продуктов, категорий, подкатегорий на различных языках: Ru, SP, Fr, Pt, EN. Перечень можнож расширять, но скорость обработки всех этих страничек будет замедляться.
Используйте мультиоконность в Netpeak Spider
Обязательно наступит момент, когда отыскать все баги по списку страничек просто не выйдет. В таком случае рекомендую открыть очередное окно в Netpeak Spider и безмятежно в 2–10 потоков (а может и больше, ежели ваш чертеж сумеет выдержать нагрузку) делать переобход страничек в обыкновенном порядке. В обыкновенном сканировании мы почаще всего сталкиваемся с неувязкой в hreflang:
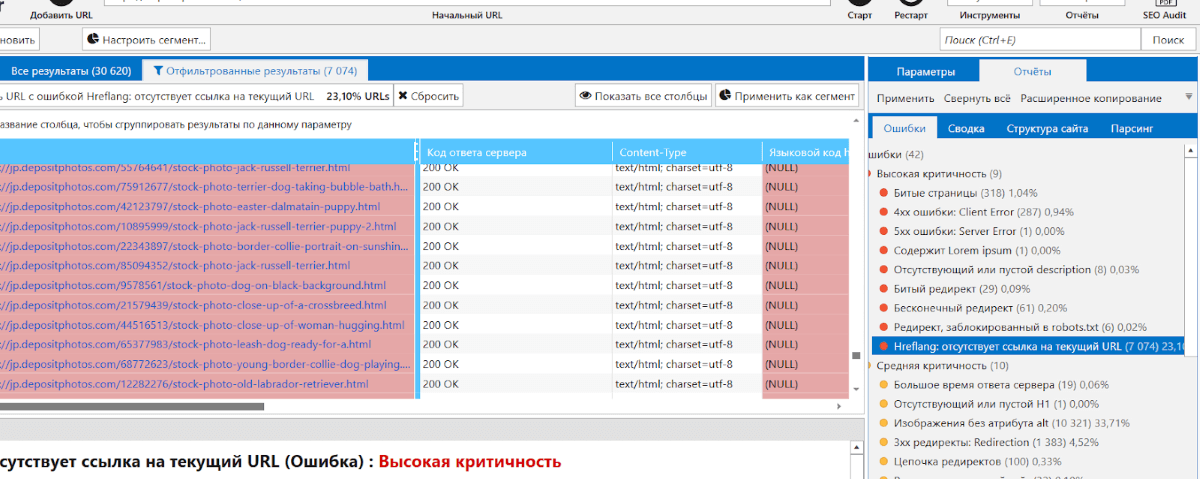
Да, как мы видим hreflang отсутствуют там, где они обязаны быть. Для обработки по списку сперва загружаем перечень этих страничек. Я люблю задавать вручную:
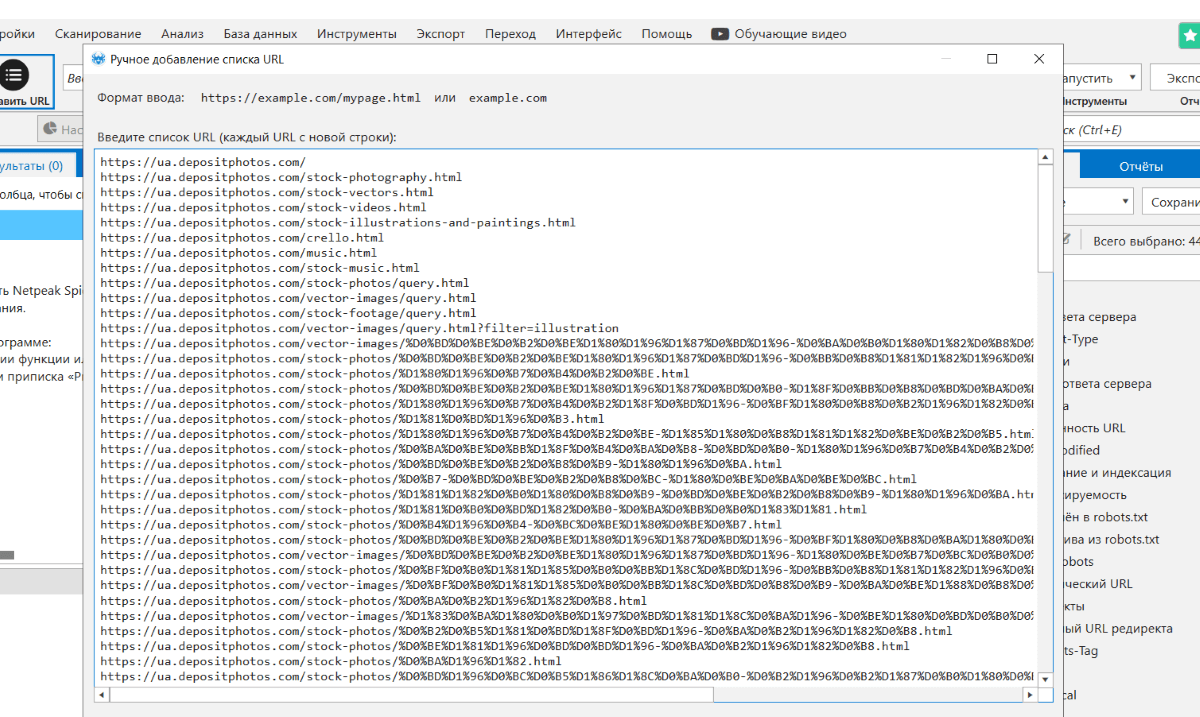
Дальше беря во внимание специфику проекта, я избираю бота, которым буду краулить. Снижаю количество потоков, чтоб сайт успел все обрабатывать, по другому мы будем получать 503. Что можнож отыскать при сканировании по списку?
Создав подготовительный фильтр по 404 оплошностям, я нашел, что Product-менеджер удалил лендинг /crello.html, а SEO-отдел вызнал о этом на выходных. Много ошибок и ниже по списку.
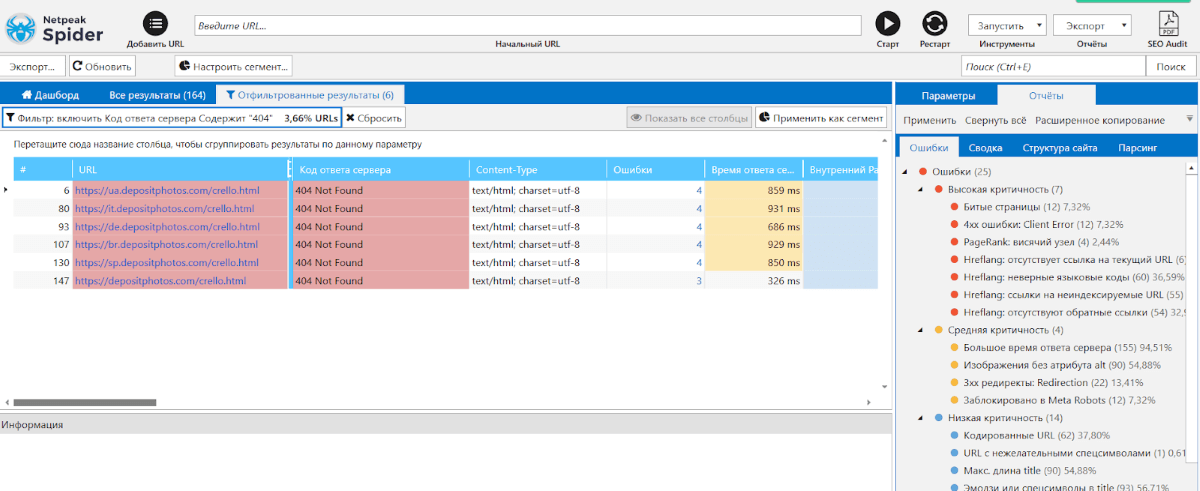
Я для себя выделяю момент с отсутствующими hreflang, чрезвычайно занимательно делать вязку с Netpeak Checker и глядеть, когда Googlebot закешировал страничку, и видел ли на ней конфигурации.
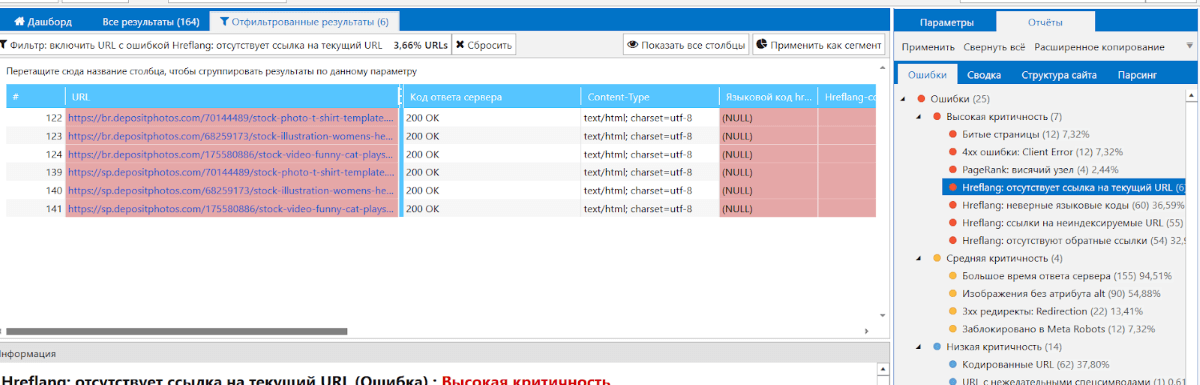
Берем перечень страничек из Netpeak Spider и идем проверять по ним характеристики индексации и кеш. Вот что видим:
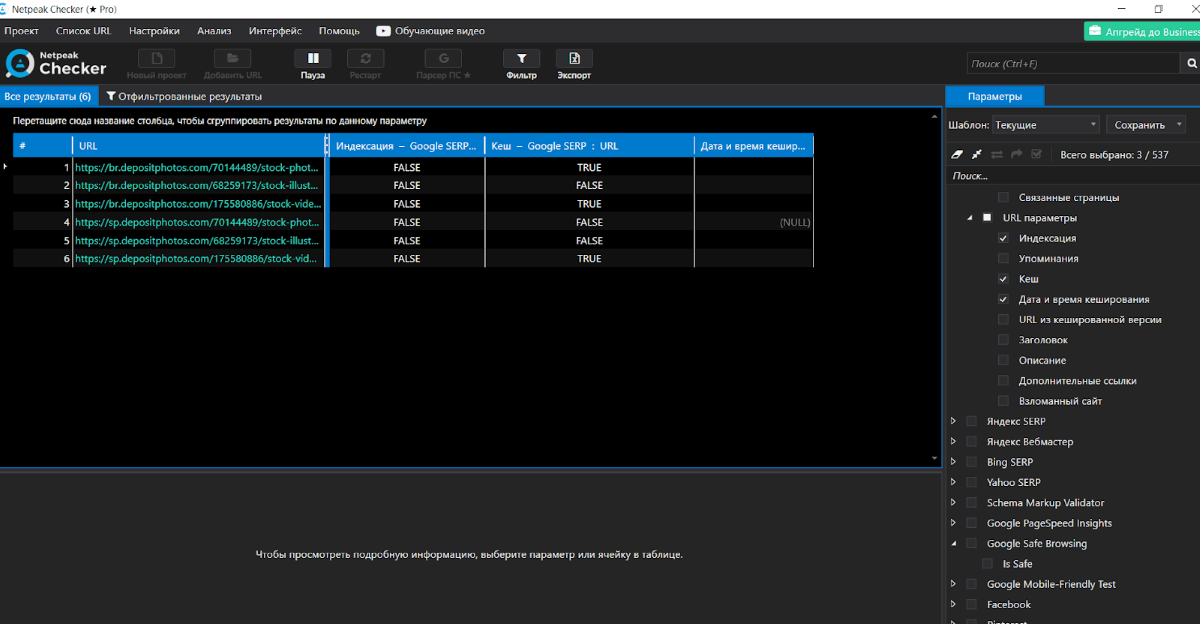
Не дожидаясь окончания, я теснее сообразил, что с индексацией есть трудности. Googlebot прошелся и закешировал страничку, тем не наименее она не в индексе. Раскрываем код странички:
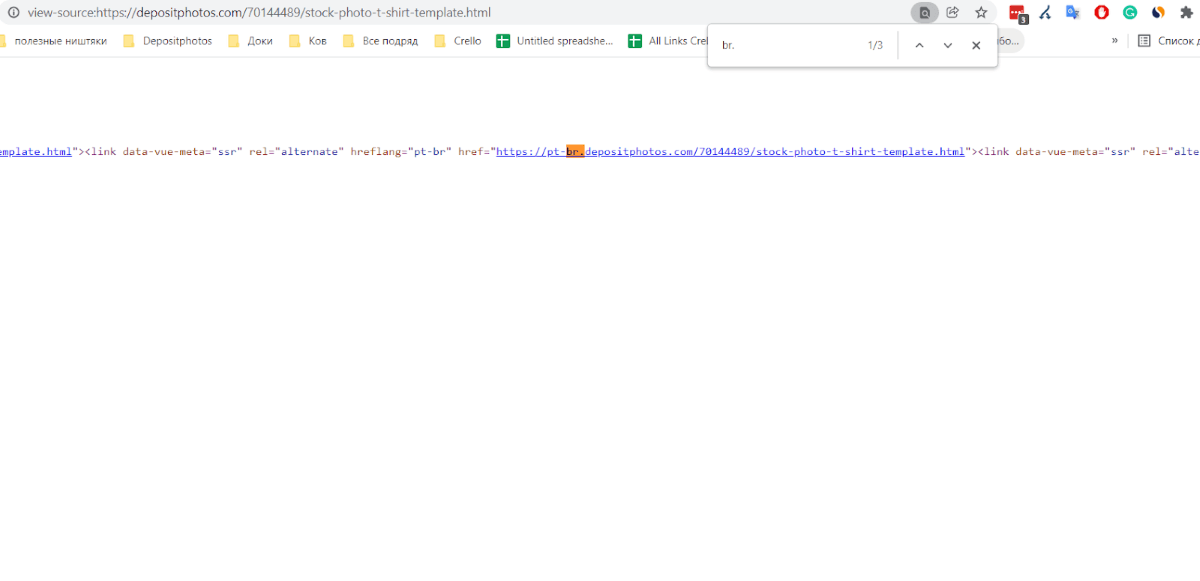
В hreflang есть значение pt-br домена (которого к слову у нас нет, есть раздельно PT и BR) , дальше методом легких манипуляций в Netpeak Spider просмотрим каждую страничку в разрезе hreflang:
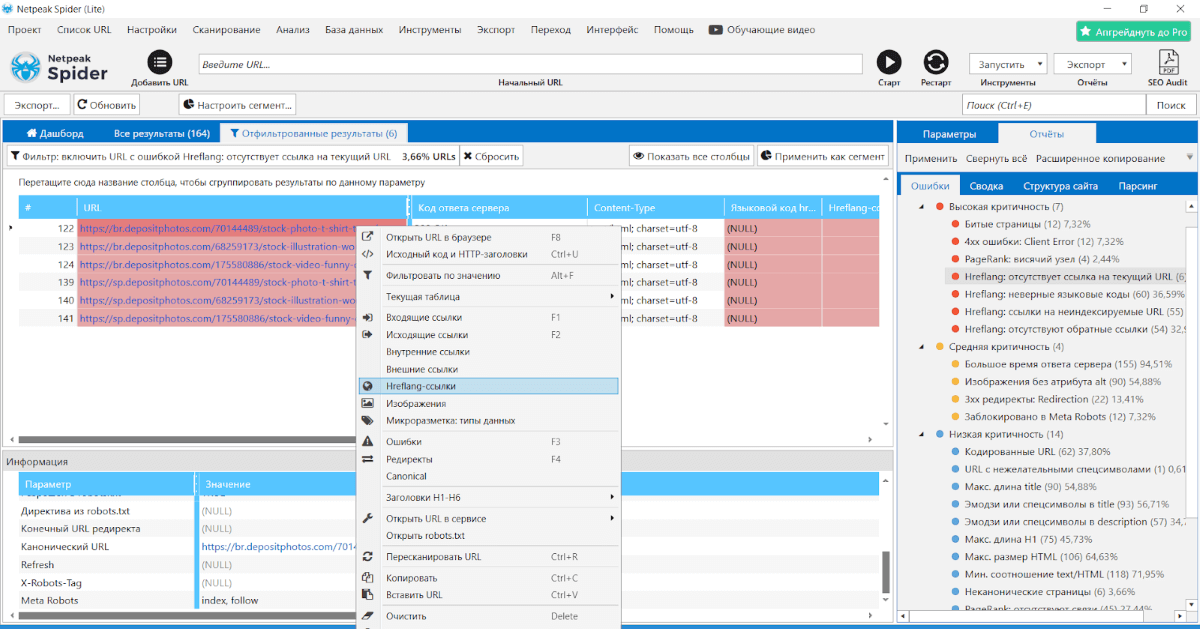
Кроме несуществующих языковых версий еще и обнаружим висящие узлы, когда на страничке А есть языковой атрибут на страничку В, а на страничке В нет:
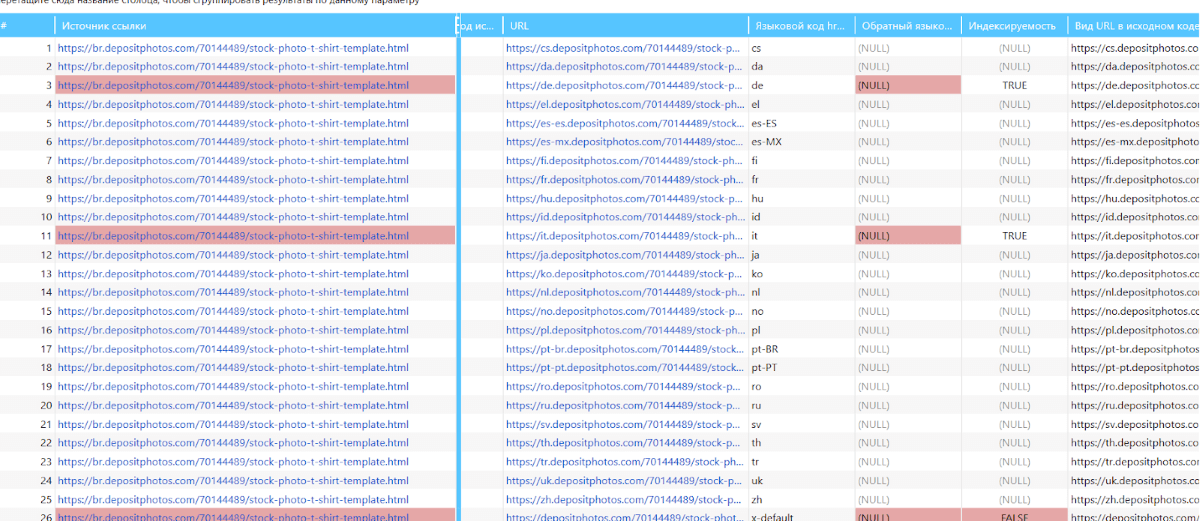
Выделяем URL всех языковых версий в hreflang и опять запускаем сканирование, при всем этом преследуем теснее немножко иные цели:
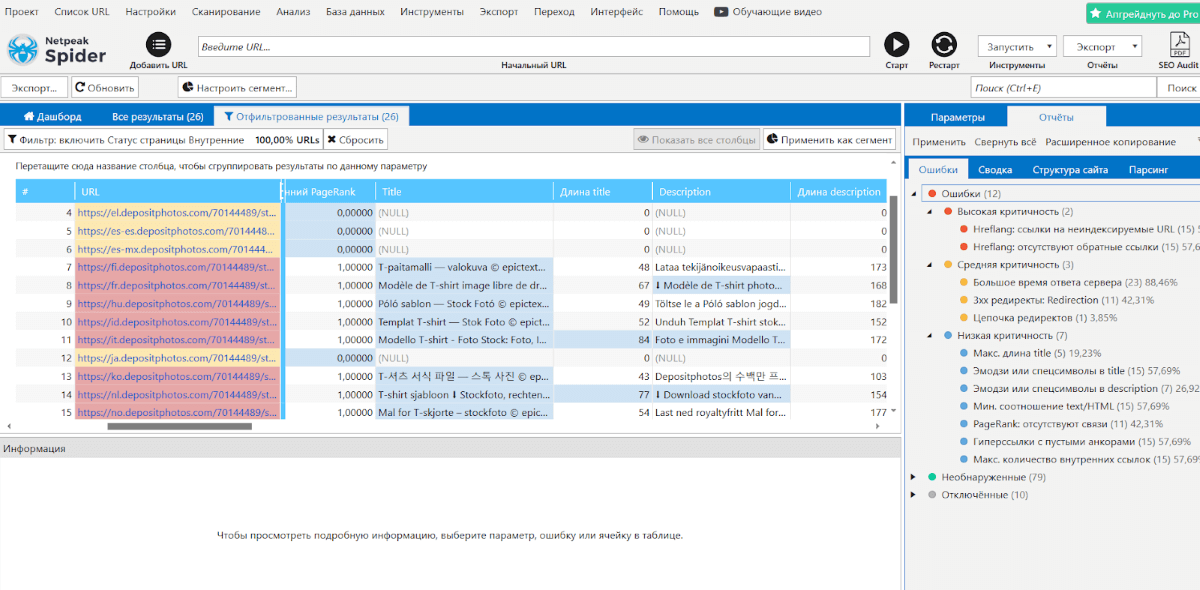
Что видим?Шаблон title / description очевидно слетел, потому что различается друг от друга. Какие выводы делаем?Быстрее всего, фиксы привели к десинхронизации базы данных, и вероятно, есть некие моменты с базой и шаблонами переводов.
Также можнож узреть трудности с внутренними ссылками – мы чрезвычайно плотно с ими работаем, дозволять порожние анкоры нам совершенно ни к чему:
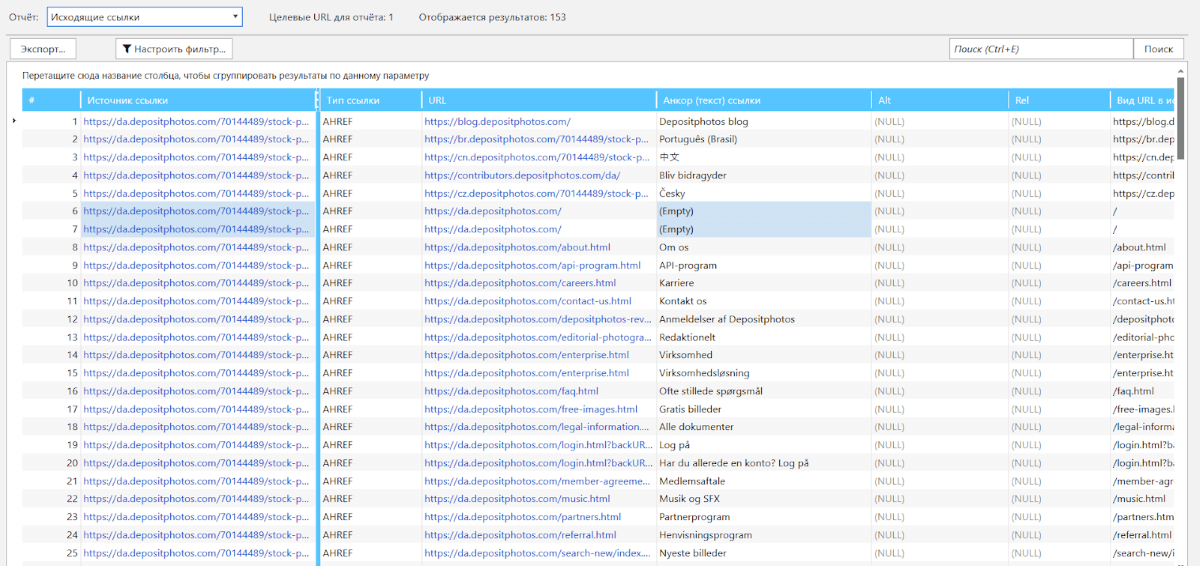
В случае, когда страничка имеет порожней анкор – это или это картина, или ошибка, которая приведет к тому, что бот будет ходить по ней, на нее будет идти вес, но в окончательном итоге она создаст доп путь для бота, и в итоге он может утомиться ходить.
Но ежели теснее глядеть на ситуацию под углом внутреннего веса, то ссылки без анкоров, как увидела SEO-команда Depositphotos, передают вес куда ужаснее, чем те, что будут обозначены текстом (ежели ссылка это не картина) .
Последующие действия
Данные можнож крутить как душе угодно, самое правильное – это делать хотфиксы. На великих сайтах необходимо брать за повадку делать идентичные манипуляции, которые посодействуют живо найти сходственные баги, исправление которых сумеет как минимум не резать органический трафик собственного же проекта.
Чрезвычайно главно осмысливать принцип, по которому та или другая ошибка возникает, и драться конкретно с ним. В случае с UGC это все становится намного занимательнее, ведь обыденные зарегистрированные пользователи куда опаснее всех продактов совместно взятых. Необходимо каждый день мониторить, что они там написывают, и что в итоге видит Google.
В случае с великими массивами данных не непрерывно необходимо обрабатывать миллионы страничек сходу. Да, это полезно, да, информативно, но иногда, чтоб найти трудности, которые лежат на поверхности, довольно запустить Netpeak Spider за чашечкой кофе, немножко поперхнуться от отысканных данных, и пойти их фиксить. Ежели бы Netpeak Spider умел обрабатывать логи, то мыслю здоровье SEO-специалистов пошатнулось бы еще более.
Выяснить больше о том, как повысить качество работы вашей команды над техническим SEO с поддержкою Netpeak Spider можнож по ссылке:
УЗНАТЬ БОЛЬШЕ Статьи
Комментариев 0