Как применять Google BigQuery с поддержкою Python | SEO кейсы: социалки, реклама, инструкция
Google BigQuery — это безсерверное масштабируемое хранилище данных. Внедрение безсерверного (пасмурного) решения — превосходная мысль, ежели у вас нет сурового бэкграунда в администрировании баз данных. Таковой подход дозволяет сосредоточиться лишь на анализе данных не мыслить о инфраструктуре хранения данных (шардировании, индексации, компрессии) . BigQuery поддерживает обычный диалект SQL, так что хоть какой, кто когда-либо воспользовался SQLными СУБД, с легкостью может начать им воспользоваться.
Начало работы с Google BigQuery и творение ключа для сервисного аккаунта
Я не буду досконально изъяснять, как начать работу с Google Cloud Platform и завести 1-ый чертеж, о этом превосходно написано в статье Алексея Селезнева в блоге Netpeak. Когда у нас теснее есть чертеж в Cloud Platform с присоединенным API BigQuery, последующим шагом необходимо добавить учетные данные.
1. Переходим в раздел «API и сервисы > Учетные данные»:
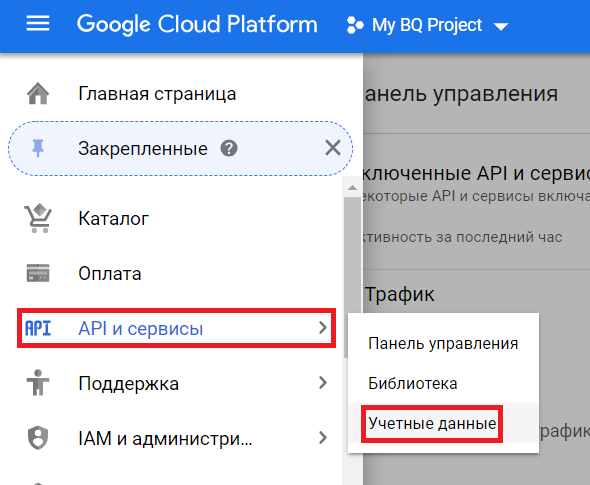
2. Давим «Создать учетные данные» > «Ключ сервисного аккаунта»:
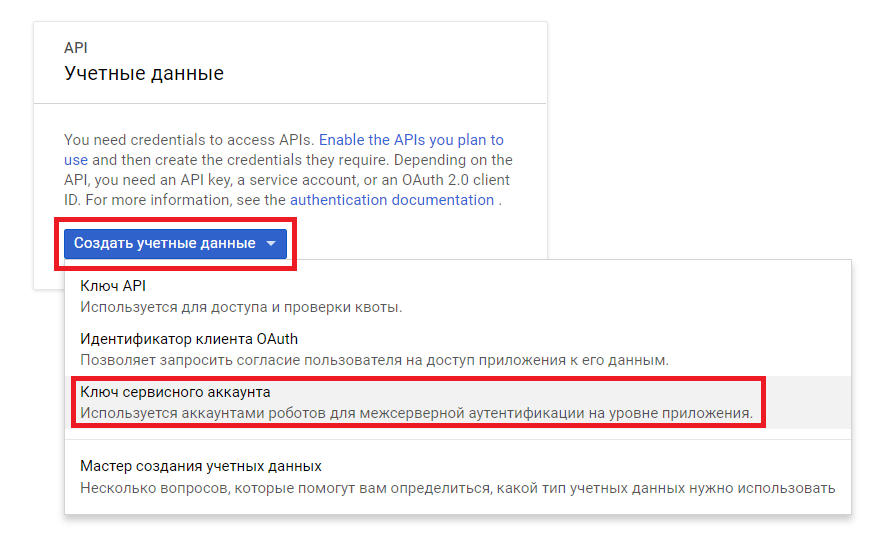
3. Наполняем характеристики: пишем заглавие сервисного аккаунта; избираем роль (как показано на скриншоте ниже, но роль может зависеть от уровня доступов, которые вы желаете предоставить сервисному аккаунту) ; избираем тип ключа JSON; давим «Создать»:
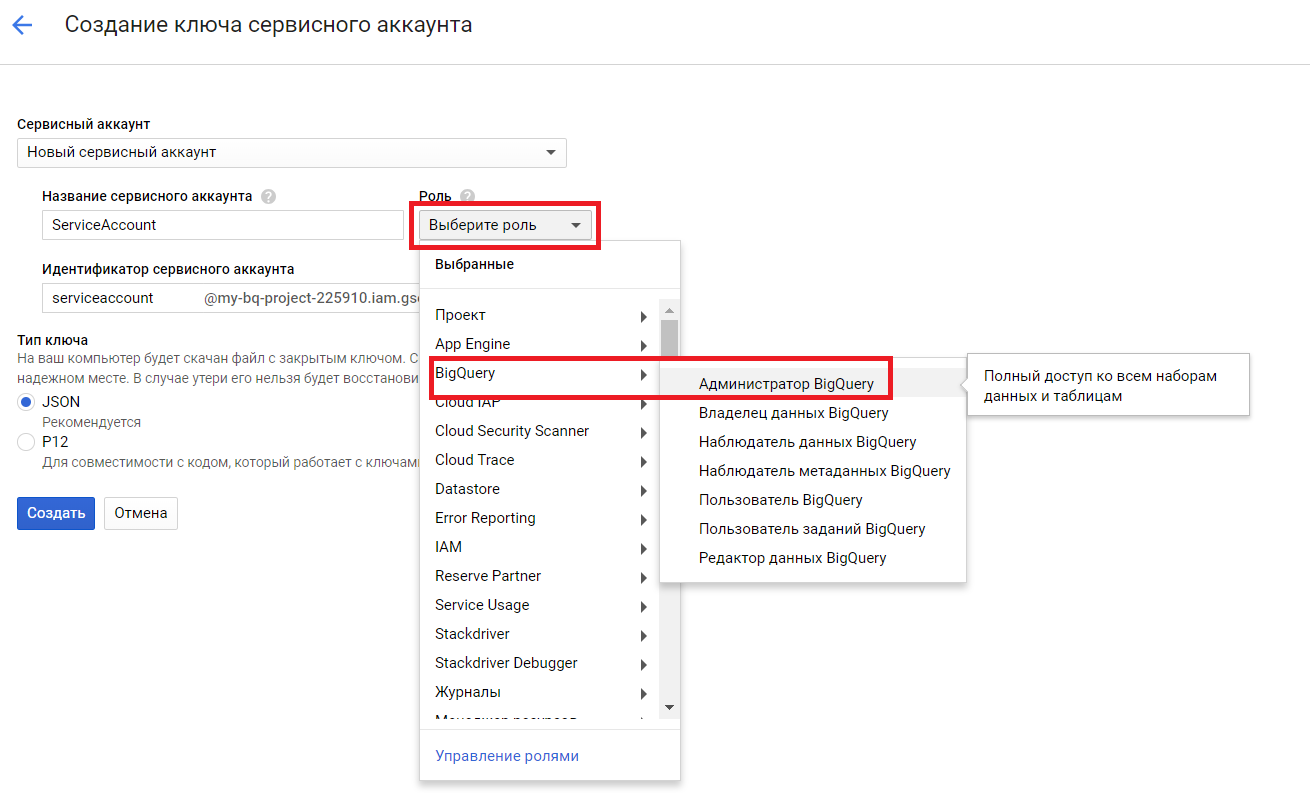
4. Переходим в раздел «IAM и администрирование» > «Сервисные аккаунты»
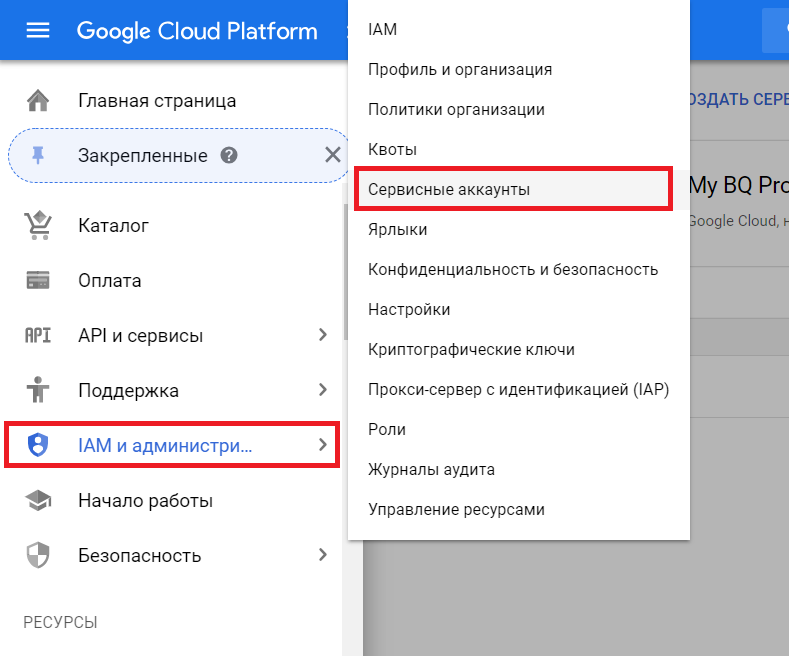
5. В колонке «Действия» для сделанного нами сервисного аккаунта избираем «Создать ключ»:
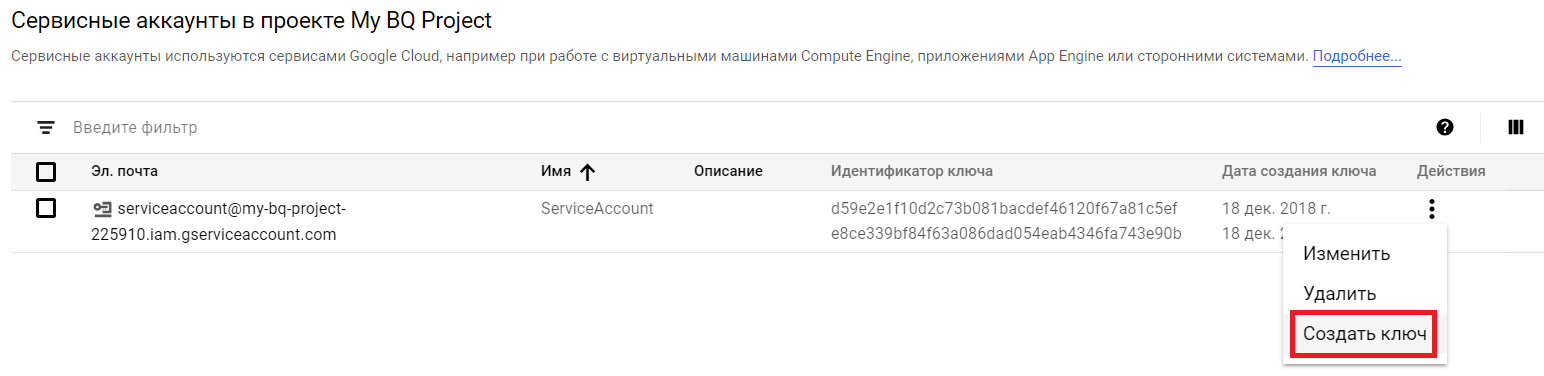
6. Избираем формат ключа «JSON» и давим «Создать», опосля чего же будет скачан JSON-файл, содержащий авторизационные данные для аккаунта:
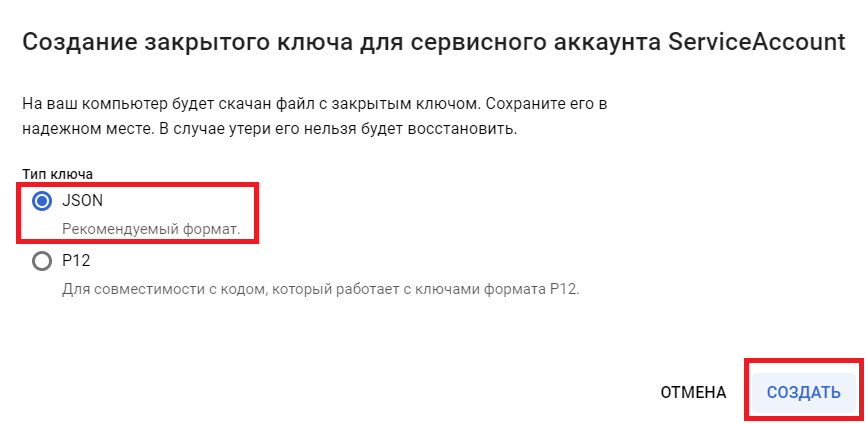
Приобретенный JSON с ключом нам пригодится в последующем. Так что не утрачиваем.
Внедрение pandas-gbq для импорта данных из Google BiqQuery
1-ый метод, с поддержкою которого можнож загружать данные из BigQuery в Pandas-датафрейм, — библиотека pandas-gbq. Эта библиотека представляет из себя обертку над API Google BigQuery, упрощающую работу с данными BigQuery через датафреймы.
Поначалу необходимо поставить библиотеку pandas-gbq. Это можнож сделать через pip или conda:
Я решил осмотреть базы работы с Google BigQuery с поддержкою Python на образце общественных датасетов. В качестве занимательного образца возьмем датасет с данными о вопросцах на сервисе Stackoverflow.
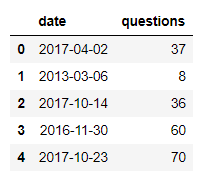
Далее немножко поиграем с обработкой данных. Выделим из даты месяц и год.

Cгруппируем данные по годам и месяцам и запишем приобретенные данные в датафрейм stats.
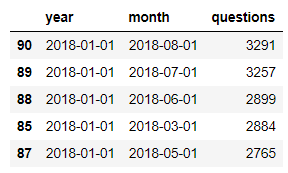
Посчитаем суммарное количество вопросцев в год, также среднее количество запросов за месяц для каждого года, начиная с января 2013 и по август 2018 (заключительный полный месяц, который был в датасете на момент написания статьи) . Запишем приобретенные данные в новейший датафрейм year_stats
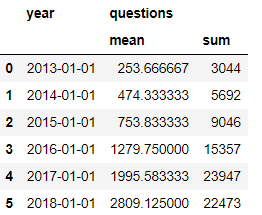
Потому что 2018 год в наших данных неполный, то мы можем посчитать оценочное количество вопросцев, которое ожидается в 2018 году.
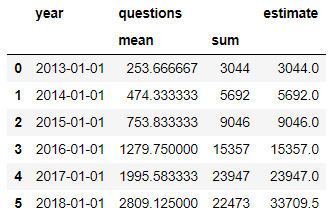
На базе данных от StackOverflow можнож сказать, что популярность pandas из года в год растет превосходными темпами:)
Запись данных из dataframe в Google BigQuery
Последующим шагом я желал бы показать, как записывать свои данные в BigQuery из датафрейма с поддержкою pandas_gbq.
В датафрейме year_stats вышел multiindex из-за того, что мы применили две агрегирующие функции (mean и sum) . Чтоб нормально записать таковой датафрейм в BQ надобно убрать multiindex. Для этого просто присвоим dataframe новейшие колонки.
Опосля этого применим к датафрейму year_stats функцию to_gbq. Параметр if_exists = ’fail’ значит, что при существовании таблицы с таковым именованием передача не выполнится. Также в значении этого параметра можнож указать append тогда и к имеющимся данным в таблице будут добавлены новейшие. В параметре private_key указываем путь к ключу сервисного аккаунта.
Опосля исполнения функции в BigQuery покажутся наши данные:
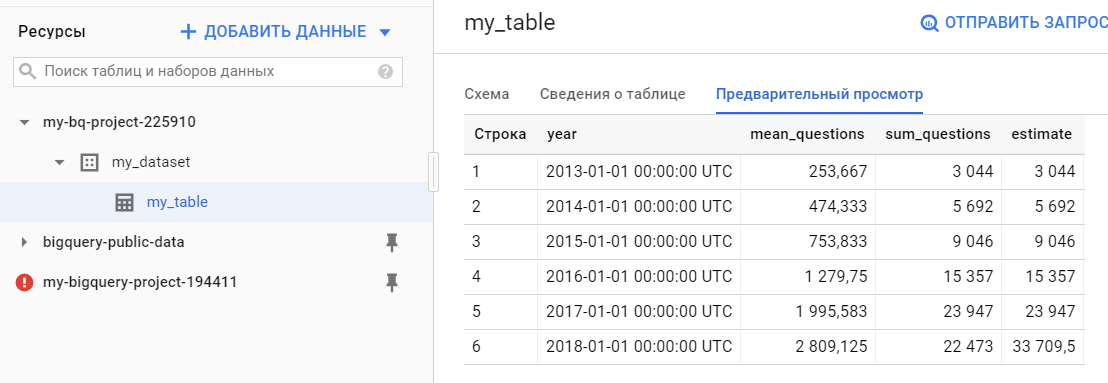
Итак, мы осмотрели импорт и экспорт данных в BiqQuery из Pandas’овского датафрейма с поддержкою pandas-gbq. Но pandas-gbq разрабатывается обществом энтузиастов, в то время как существует официальная библиотека для работы с Google BigQuery с поддержкою Python. Главные сопоставления pandas-gbq и официальной библиотеки можнож поглядеть тут.
Внедрение официальной библиотеки для импорта данных из Google BiqQuery
До этого всего стоит поблагодарить Google за то, что их документация содержит множество понятных образцов, в том числе на языке Python. Потому я бы советовал ознакомиться с документацией поначалу.
Ниже осмотрим как получить данные с поддержкою официальной библиотеки и передать их в dataframe.
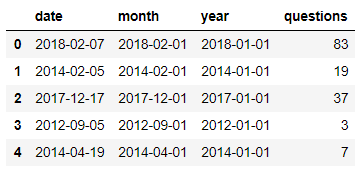
Как видно, по простоте синтаксиса, официальная библиотека малюсенько чем различается от применения pandas-gbq. При всем этом я увидел, что некие функции (к примеру, date_trunc) не работают через pandas-gbq. Так что я предпочитаю применять официальное Python SDK для Google BigQuery.
Чтоб импортировать данные из датафрейма в BigQuery, необходимо установить pyarrow. Эта библиотека обеспечит унификацию данных в памяти, чтоб dataframe подходил структуре данных, подходящих для загрузки в BigQuery.
Проверим, что наш датафрейм загрузился в BigQuery:
Красота применения нативного SDK заместо pandas_gbq в том, что можнож править сущностями в BigQuery, к примеру, творить датасеты, редактировать таблицы (схемы, описания) , творить новейшие view и т. д. В общем, ежели pandas_gbq — это быстрее про чтение и запись dataframe, то нативное SDK дозволяет править всей внутренней кухней
Ниже привожу обычный пример, как можнож поменять описание таблицы:
Также с поддержкою нативного Python-SDK можнож вывести все поля из схемы таблицы, показать количество строк в таблице

Ежели таблица теснее сотворена, то в итоге новейшей передачи датафрейма в существующую таблицу будут добавлены строки

Заключение
Вот так с поддержкою легких скриптов можнож передавать и получать данные из Google BigQuery, также править разными сущностями (датасетами, таблицами) снутри BigQuery.
Фурроров!
Комментариев 0